
「メタゲノミクス」の版間の差分
Karasunoko (会話 | 投稿記録) 編集の要約なし |
Karasunoko (会話 | 投稿記録) →ショットガンシーケンシングの登場: +ref |
||
| 22行目: | 22行目: | ||
かつては環境サンプルから数千[[塩基対]]よりも長いDNA断片の回収することは困難であったが、分子クローニング用の[[ベクター (遺伝子工学)|ベクター]]としてBAC([[:en:Bacterial_artificial_chromosome|bacterial artificial chromosomes]])が開発されたことにより、ライブラリーの構築が可能になった。現在では次世代シーケンサーの登場により、BACライブラリを経ることなくより大量の配列情報を取得することが可能である。(詳細は[[DNAシークエンシング|DNAシーケンシング]]を参照) |
かつては環境サンプルから数千[[塩基対]]よりも長いDNA断片の回収することは困難であったが、分子クローニング用の[[ベクター (遺伝子工学)|ベクター]]としてBAC([[:en:Bacterial_artificial_chromosome|bacterial artificial chromosomes]])が開発されたことにより、ライブラリーの構築が可能になった。現在では次世代シーケンサーの登場により、BACライブラリを経ることなくより大量の配列情報を取得することが可能である。(詳細は[[DNAシークエンシング|DNAシーケンシング]]を参照) |
||
=== ショットガンシーケンシングの登場 === |
=== ショットガンシーケンシングの登場 === |
||
[[バイオインフォマティクス]]の進歩、DNA増幅([[PCR]])法の改良、および計算機能力の急増により、環境サンプルから得られるDNA配列の分析能力は飛躍的に向上し、[[ショットガン・シークエンシング法|ショットガンシーケンス]]をメタゲノムサンプルに応用することが可能になった。これは全メタゲノムショットガンシーケンス、または英語(<u>W</u>hole <u>M</u>eta<u>g</u>enome Shotgun <u>S</u>equence)からWMGSと呼ばれることがある。培養微生物から[[ヒトゲノム計画|ヒトゲノム]]に至るまで、大半の全ゲノム解読を行う研究においては、DNAをランダムに短く切断し、それらのDNA断片を大量にシーケンスし、得られた配列情報のアセンブリを経てコンセンサス配列を再構築する、というステップを経る。このようなプロセスを経ることで、ショットガンシーケンシングを行ったメタゲノム解析では、環境サンプル中に存在する細菌叢に由来するゲノム配列を系統網羅的に取得することが可能である。歴史的には、このようなショットガンシーケンスを容易にするために、BAC等を利用したクローンライブラリが使用されてきた。ショットガンシーケンスを解析することで、菌叢内でどのような系統群の生物が存在し、どのような[[代謝]]プロセスが行われているのか、等について明らかにすることができる。原理的には、環境サンプル中に含まれているそれぞれの微生物系統の細胞量の違いによって回収されるDNA量も変わってくるため、その環境サンプル内で最も多く存在する生物種(優占種)は大量にシーケンスされ、配列情報も多く得ることができる。そのため優占種については完全長のゲノム配列を得ることも可能である<ref name=Tyson2004/>。一方で、存在量の少ない生物種(そのサンプルにおける希少種)では解析に十分な量の配列情報が得られない可能性があり、そのような希少生物種のゲノムを完全に決定するためにはより高いカバレッジが必要になり、合わせて非常に多くのサンプルが必要となる。このことは反面、ショットガンシーケンスは原理的には完全ランダムにDNA断片のシーケンスを行うため、従来の[[培養]]ベースの手法では見過ごされていた未培養微生物系統であっても、大なり小なりゲノム情報を得ることができる、ということでもある。 |
[[バイオインフォマティクス]]の進歩、DNA増幅([[PCR]])法の改良、および計算機能力の急増により、環境サンプルから得られるDNA配列の分析能力は飛躍的に向上し、[[ショットガン・シークエンシング法|ショットガンシーケンス]]をメタゲノムサンプルに応用することが可能になった。これは全メタゲノムショットガンシーケンス、または英語(<u>W</u>hole <u>M</u>eta<u>g</u>enome Shotgun <u>S</u>equence)からWMGSと呼ばれることがある<ref>{{Cite journal|last=Jiang|first=Bai|last2=Song|first2=Kai|last3=Ren|first3=Jie|last4=Deng|first4=Minghua|last5=Sun|first5=Fengzhu|last6=Zhang|first6=Xuegong|date=2012|title=Comparison of metagenomic samples using sequence signatures|url=http://bmcgenomics.biomedcentral.com/articles/10.1186/1471-2164-13-730|journal=BMC Genomics|volume=13|issue=1|pages=730|language=en|doi=10.1186/1471-2164-13-730|issn=1471-2164|pmid=23268604|pmc=PMC3549735}}</ref>。培養微生物から[[ヒトゲノム計画|ヒトゲノム]]に至るまで、大半の全ゲノム解読を行う研究においては、DNAをランダムに短く切断し、それらのDNA断片を大量にシーケンスし、得られた配列情報のアセンブリを経てコンセンサス配列を再構築する、というステップを経る<ref>{{Citation|title=ヒト腸内細菌叢のゲノムシークエンス|first2=哲也|first5=知巳|last4=伊藤|first4=武彦|last3=黒川|first3=顕|last2=林|last=服部|url=https://doi.org/10.11209/jim.21.187|first=正平|language=ja|doi=10.11209/jim.21.187|accessdate=2020-05-25|date=2007|publisher=公益財団法人 腸内細菌学会|last5=桑原}}</ref>。このようなプロセスを経ることで、ショットガンシーケンシングを行ったメタゲノム解析では、環境サンプル中に存在する細菌叢に由来するゲノム配列を系統網羅的に取得することが可能である。歴史的には、このようなショットガンシーケンスを容易にするために、BAC等を利用したクローンライブラリが使用されてきた。ショットガンシーケンスを解析することで、菌叢内でどのような系統群の生物が存在し、どのような[[代謝]]プロセスが行われているのか、等について明らかにすることができる。原理的には、環境サンプル中に含まれているそれぞれの微生物系統の細胞量の違いによって回収されるDNA量も変わってくるため、その環境サンプル内で最も多く存在する生物種(優占種)は大量にシーケンスされ、配列情報も多く得ることができる。そのため優占種については完全長のゲノム配列を得ることも可能である<ref name=Tyson2004/>。一方で、存在量の少ない生物種(そのサンプルにおける希少種)では解析に十分な量の配列情報が得られない可能性があり、そのような希少生物種のゲノムを完全に決定するためにはより高いカバレッジが必要になり、合わせて非常に多くのサンプルが必要となる。このことは反面、ショットガンシーケンスは原理的には完全ランダムにDNA断片のシーケンスを行うため、従来の[[培養]]ベースの手法では見過ごされていた未培養微生物系統であっても、大なり小なりゲノム情報を得ることができる、ということでもある。 |
||
=== 次世代シーケンシング技術の活用 === |
=== 次世代シーケンシング技術の活用 === |
||
2020年5月25日 (月) 09:01時点における版

メタゲノミクス(英:Metagenomics)は、環境サンプルから直接回収されたゲノムDNAを扱う微生物学・ウイルス学の研究分野である。広義には環境ゲノミクスやエコゲノミクス、群集ゲノミクスとも呼ばれる[1]。メタゲノム解析(Metagenomic analysis)、あるいは単純にメタゲノム(Metagenome)とも呼称される。従来の微生物のゲノム解析では、単一の菌株を環境サンプルから分離培養する過程を経る必要があったが、メタゲノム解析はこの過程を経ることなく、微生物コミュニティ(細菌叢)から直接ゲノムDNAを抽出し、様々な系統由来のDNAがミックスされた状態でDNAシーケンスを行う。そのため、メタゲノム解析では従来の培養を基本とする方法では困難であった難培養・未培養系統に属する微生物のゲノム情報が入手可能である。一説には、地球上に棲息する細菌の99%以上は単独では培養できない系統であると推察されており[2]、メタゲノム解析は環境中に埋没する膨大な数の未知の細菌、未知の遺伝子を解明できる手法として期待されている。DNAシークエンシングのコストは年々安価になってきており、より大規模で詳細なメタゲノム解析研究が行われることも見込まれる[3]。狭義には、メタゲノム解析はショットガンシーケンスにより得られたゲノム全体の配列情報を解析することを指し、ターゲット遺伝子を絞りPCRを経た増幅シーケンス(16S rRNAタグシーケンスなど)とは区別されるが[4]、後者を広義のメタゲノム解析に含めて扱われることもある[5]。
今日では、海水や土壌、腸内や口腔といった様々な常在細菌叢、海底の鯨骨細菌群、鉱山廃水中のバイオフィルム、動植物の共生細菌、下水処理施設、南極氷床、温泉、大深層の地殻など、様々な環境を対象としたメタゲノム解析が論文として報告されている[6]。
語源
メタゲノムという用語は、「ゲノム」に高次元を表す「メタ」という言葉を付け加えて命名された[7]。単一生物のゲノムを研究するのと同じように、環境中からゲノムの遺伝子配列を収集し纏めて(メタ的に)解析をすることが可能である、という考えが元にある。この用語はJo Handelsman, Jon Clardy, Robert M. Goodman, Sean F Bradyらにより1998年に初めて論文内で使用された[7]。Kevin ChenとLior Pachterは2005年にメタゲノム解析を「個々の菌を研究室内で単離したり培養したりする必要がない現代ゲノム技術の応用分野」と定義している[8]。
歴史と背景
従来のDNAシーケンスは、単一の細菌株を培養することが最初に必要であった。しかし初期のメタゲノム解析の研究により、多くの環境には培養が不可能でシーケンスが困難な微生物が多く存在することが明らかにされた。これらの初期の研究では16S rRNA遺伝子配列を調べることに焦点が当てられた。この遺伝子配列は比較的短く、原核生物種内において保存性が高い一方で、異なる種間で変化が見られるため、ゲノム全体をシーケンスするよりも簡便に環境中の微生物群集を系統的に調べることが出来る。多くの環境サンプルに対して16S rRNA遺伝子配列のDNAシーケンスが実施され、その結果、培養されている既知の生物種には当てはまらない配列が多数見つかった。このことはすなわち、環境中には極めて多様な未培養系統群の微生物が存在していることを示している。このようにして16S rRNA遺伝子配列を培養を経ず環境中から直接得た研究により、培養を元にした方法で見つけられる試料中の真性細菌・古細菌は全体の1%に満たないことが論文で報告された[9]。
PCRを使用してリボソームRNA配列の多様性を調査するという初期の分子生物学的な研究は、ノーマンR.ペースと同僚によって行われた[10]。これらの先駆的な研究から得られた知見から発展して、環境試料から直接DNAをクローニングするアイデアが1985年に発表された[11]。そして、実際に大西洋の海水という環境サンプルからDNAを抽出してクローニングした最初の報告が、Paceらによって1991年に発表された[12]。これらがPCR偽陽性ではないことが相当な努力により示され、未探索の系統群によって形作られる複雑な微生物コミュニティの存在が示唆された。この方法論は、高度に保存された非タンパク質コード遺伝子の探索に限定されていたが、培養方法で知られていたよりもはるかに複雑な多様性が存在するという、初期の微生物形態ベースの観察結果をサポートしていた。すぐその後、Healyは実験室に置いていた乾燥した草の上で増殖していた環境微生物の複合培養物から構築した「動物園ライブラリ」(zoolibraries)とでも呼ぶべきものから、機能遺伝子をメタゲノム的に単離したと1995年に報告した[13]。その後Edward DeLongらは、海洋サンプルからライブラリー構築と16S rRNAシーケンスを実施し、環境中の原核生物を系統的に解析する研究の基礎を築いた[14]。
2002年、Mya BreitbartとForest Rohwerらは、ショットガンシーケンスを使用して、200リットルの海水に5000種類以上のウイルスが含まれていることを示した[15]。その後の研究により、ヒトの糞便には1000種以上のウイルス種が存在し、また海洋堆積物1キログラムあたりには多くのバクテリオファージを含む百万種ものウイルスが存在する可能性があることが示された。そして、これらの研究で見つかったウイルスは大半が新種であった。2004年には、Gene TysonとJill Banfieldらは、酸性の鉱山排水システムから抽出された細菌叢DNAの配列を決定した[16]。この研究では、培養が試みられつつも成功していなかった少数の細菌および古細菌系統の、完全またはほぼ完全なゲノムが得られている。
2003年からは、ヒトゲノムプロジェクトに並行して進められた民間資金ベースのプロジェクトをリーダーとして率いていたCraig Venterが、グローバル・オーシャン・サンプリング・エクスペディション(GOS)を主導し、世界中を周回する旅を通じてメタゲノムサンプルを蒐集した。得られたサンプルはすべて、新規なゲノム(すなわち新規生物)が特定されることを期待して、ショットガンシーケンスが実施された。これに先駆けて実施されたパイロットプロジェクトでは、サルガッソー海で採取したサンプルの解析を行い、約2000種もの異なるDNAを発見し、内148種は新規な細菌種に由来すると考えられた[17]。ベンターは地球を一周し、米国西海岸を集中的にサンプリングし、さらに2年間をかけてバルト海、地中海、黒海でサンプリングを行った。この間に収集されたメタゲノムデータの分析により海洋表層の細菌層は、富栄養/貧栄養の環境条件に適応した分類群と、比較的少ないがより豊富で広く分布する主にプランクトンで構成される分類群という、2つのグループによって構成されていることが判明した[18]。
2005年、ペンシルベニア州立大学のStephan C. Schusterらは、ハイスループットシーケンスで生成された環境サンプルの最初のシーケンスを公開した[19]。これは454 Life Sciences社が開発した超並列パイロシーケンスによるものであった。この分野の別の初期の論文は、2006年にサンディエゴ州立大学のRobert EdwardsとForest Rohwerらよって発表された[20]。
ゲノムシーケンシング

かつては環境サンプルから数千塩基対よりも長いDNA断片の回収することは困難であったが、分子クローニング用のベクターとしてBAC(bacterial artificial chromosomes)が開発されたことにより、ライブラリーの構築が可能になった。現在では次世代シーケンサーの登場により、BACライブラリを経ることなくより大量の配列情報を取得することが可能である。(詳細はDNAシーケンシングを参照)
ショットガンシーケンシングの登場
バイオインフォマティクスの進歩、DNA増幅(PCR)法の改良、および計算機能力の急増により、環境サンプルから得られるDNA配列の分析能力は飛躍的に向上し、ショットガンシーケンスをメタゲノムサンプルに応用することが可能になった。これは全メタゲノムショットガンシーケンス、または英語(Whole Metagenome Shotgun Sequence)からWMGSと呼ばれることがある[21]。培養微生物からヒトゲノムに至るまで、大半の全ゲノム解読を行う研究においては、DNAをランダムに短く切断し、それらのDNA断片を大量にシーケンスし、得られた配列情報のアセンブリを経てコンセンサス配列を再構築する、というステップを経る[22]。このようなプロセスを経ることで、ショットガンシーケンシングを行ったメタゲノム解析では、環境サンプル中に存在する細菌叢に由来するゲノム配列を系統網羅的に取得することが可能である。歴史的には、このようなショットガンシーケンスを容易にするために、BAC等を利用したクローンライブラリが使用されてきた。ショットガンシーケンスを解析することで、菌叢内でどのような系統群の生物が存在し、どのような代謝プロセスが行われているのか、等について明らかにすることができる。原理的には、環境サンプル中に含まれているそれぞれの微生物系統の細胞量の違いによって回収されるDNA量も変わってくるため、その環境サンプル内で最も多く存在する生物種(優占種)は大量にシーケンスされ、配列情報も多く得ることができる。そのため優占種については完全長のゲノム配列を得ることも可能である[16]。一方で、存在量の少ない生物種(そのサンプルにおける希少種)では解析に十分な量の配列情報が得られない可能性があり、そのような希少生物種のゲノムを完全に決定するためにはより高いカバレッジが必要になり、合わせて非常に多くのサンプルが必要となる。このことは反面、ショットガンシーケンスは原理的には完全ランダムにDNA断片のシーケンスを行うため、従来の培養ベースの手法では見過ごされていた未培養微生物系統であっても、大なり小なりゲノム情報を得ることができる、ということでもある。
次世代シーケンシング技術の活用
今日では次世代シーケンサー(ハイスループットシーケンシング技術)の登場と進歩により、クローニングのステップを省略してシーケンスデータの収量を増やすことが可能である。次世代シーケンスを使用して実施された最初のメタゲノム研究では、454パイロシーケンシングが利用された[23]。その後、Ion Torrent Personal Genome Machineや、Illumina MiSeq、HiSeq、Applied Biosystems SOLiDシステム等が登場し、メタゲノム解析に利用されるようになった[24]。これらの次世代DNAシーケンシング技術で得られるリードはサンガーシーケンスよりも短い。具体的には、サンガー法では750bp程度のリードを得られるのに対し、Ion Torrent PGM Systemや454パイロシーケンシングでは約400bp、Illumina MiSeqでは最大600bp、SOLiDは25-75bp程度である(2008年のカタログスペック値)[25]。一方で、次世代シーケンシングでは圧倒的に多量のDNA配列を読むことができ、具体的には454パイロシーケンスでは200〜500Mb、Illuminaプラットフォームでは20〜50Gbもの配列情報を排出し(2009年のカタログスペック値)、またこの値は年々増加している[26]。
新しい技術の活用
2010年にPacBio RSが発売されたことを皮切りに、次世代シーケンサーよりも更に長いロングリードを読むことができる、いわゆる第3世代シーケンサーが、PacBio社(1分子リアルタイムシーケンシング)やNanopore社から登場している。このような第3世代シーケンシング技術をメタゲノム解析に応用することで、ロングリードのショットガンシーケンスの取得とさらに効率できなゲノムアセンブリが可能になると考えられる[27]。また、ショットガンシーケンスと染色体コンフォメーションキャプチャ(Hi-C)法を組み合わせることで、同じ細胞内で近接するDNA断片の情報を得ることができ、この情報を活用して微生物ゲノムのアセンブリを効率化する研究も報告されている[28]。
バイオインフォマティクス解析
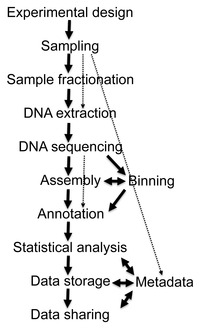
ショットガンシーケンスから得られるデータは膨大であり、ノイズが多く、ときには数万を超える生物種に由来するDNA配列がミックスされている。例えば牛のルーメンをサンプルとして実施されたメタゲノム解析では279Gpもの配列データが得られ[30]、またヒト腸内細菌叢を対象とした研究では567.7Gbの配列情報から330万個の遺伝子カタログを作成した研究が報告されている[31]。このようなビッグデータから有用な生物学的情報を収集、管理、抽出することは、本質的に重要なバイオインフォマティクス上の課題となっている[32][27]。
シーケンス配列のフィルタリング
メタゲノムデータ分析の最初のステップでは、シーケンシングの後、冗長な配列や低品質な配列、そしてヒトを含む真核生物に由来すると思われる配列の除去などを行う、事前フィルタリングを行うことが多い[33][34]。混入した真核生物ゲノムDNA配列の除去には、Eu-DetectやDeConseqなどのツールが利用可能である[35][36]。
ゲノムアセンブリ
(詳細は配列アセンブリングを参照)
ゲノムプロジェクトやメタゲノムプロジェクトにおいては、扱うDNA配列データの基本的構造は同じである。しかしながら、前者では単一種由来の配列データをより高いカバレッジで得ることが容易である一方で、後者は異なる生物種由来の配列がミックスされている分、データの冗長性が非常に低い(データセット中で同じ配列が低頻度でしか現れない)ことが多い。さらに、第2世代のシーケンシング技術はリード長が短く、そのためゲノムアセンブリでエラー(ミスアセンブリ)が頻発し、得られた結果の信頼性が低くなる事がある。特にトランスポゾンなどに代表されるゲノム中の反復配列の存在は、このようなミスアセンブリを誘発しやすい[37]。また、異なる複数種由来の配列を誤ってアセンブリしてしまう、いわゆるキメラコンティグを作り出すようなミスアセンブリも起きうる[38]。
このようなエラーを最小限にし、かつできるだけ長くアセンブリが繋がるように、様々なツール(アセンブラ)が現在も開発されている。多くアセンブラは精度を向上させるためにIlluminaのペアエンドリードの情報を利用する。PhrapやCelera Assemblerなどの一部のプログラムは、単一のゲノムをアセンブルするために設計されているが、それにも関わらずメタゲノムデータセットにおいても良好なアセンブル結果を生み出すことが経験的に知られている[39]。Velvetなどの他のプログラムでは内部でde Bruijnグラフのアルゴリズムを使用しており、第2世代シーケンサーから生成されるショートリード用に最適化されている[40][41]。リファレンスゲノムを使用することでアセンブリを改善するアプローチも提案されているが、この方法は既にゲノムが読まれている限られた微生物系統にしか適応できない[37]。アセンブリが作成された後、そのコンティグがどの系統に由来しているのかを推定することも、技術上の課題である[42]。
配列からの遺伝子予測
アセンブルされたコンセンサス配列(コンティグ)から遺伝子配列(コーディング領域)をアノテーションする方法としては、大きく分けて2つのアプローチが取られる[37]。1つ目は、BLAST等のツールを用いた配列類似性検索により、配列データベース上で公開されている遺伝子との配列類似性に基づいて遺伝子を識別する方法である。この方法は、例えばMEGAN 4で実装されている[43]。2番目の方法としては、関連する生物種(すなわち、原核生物か真核生物か)に由来した既知の配列情報から、遺伝子配列に関する特徴量を学習し、コンティグ配列から直接遺伝子領域を予測する方法である。例えばGeneMarkやGLIMMERといったプログラムで採用されている[44]。このab initioな予測方法では、配列データベースに類似したものがない新規性のあるコーディング領域も検出できることができる[45]。その後、予測された遺伝子配列を元に、公共の遺伝子データベースを用いた配列類似性検索をかけることで、その遺伝子が持つ機能を推定することが一般に行われる。
配列の系統推定

遺伝子アノテーションにより「それが何なのか(どういう機能を持つ遺伝子なのか)」という情報がわかる一方で、配列の由来系統の推定により「それが誰なのか(どういう微生物系統群に由来した配列なのか)」という情報を得ることも重要になる[47]。すなわち、メタゲノム解析で菌叢の構成と生理学的機能を結び付けるためには、アセンブリされる前のショットガンリードあるいはアセンブリ後に得られるコンティグ配列が、元々どのような生物系統に由来していたのかを推定する、配列の由来系統推定を行う必要がある。配列類似性に基づく方法としては、BLASTなどのツールと既存の公共データベースを利用して、各系統に特異的なマーカー配列や類似したゲノム上の配列を検索することで、その配列やコンティグがどのような系統に由来していたのかを推定する方法がある。このアプローチはMEGANで実装されている[48]。異なる手法としては補間マルコフモデルを使用した方法があり、PhymmBLなどで実装されている。MetaPhlAnおよびAMPHORAでは、より高速に生物の相対存在量を推定するための、マーカー遺伝子をベースとした手法が実装されている[49]。mOTU[50][51]やMetaPhyler[52]などのツールでは、ユニバーサルなマーカー遺伝子を使用して原核生物種のプロファイルを作成する。mOTUs profilerを使用すると、参照ゲノムなしで系統をプロファイリングでき、微生物群集の多様性の推定ができる[53]。SLIMMなどの手法では、個々のリファレンスゲノムにおけるリードカバレッジの分布を調べることで、偽陽性を最小限に抑えて信頼性のある相対存在量を計算する[54]。一方、組成に基づく系統推定の手法では、オリゴヌクレオチドの頻度やコドン使用頻度のバイアスなどの情報を利用する[55]。配列の由来系統が推定できることで、はじめて菌叢の系統的多様性が比較分析できるようになる。
メタデータとの統合
今日、メタゲノムを含むあらゆるゲノム配列データは指数関数的に増加しており、膨大な量のデータがデータベースに蓄積されている。特にメタゲノム解析では、個々のメタゲノム解析プロジェクトとそれに関連するメタデータとの関係が複雑であり、データ量が増加することでより一層全体が複雑化することが課題となっている。メタデータには、メタゲノム解析に用いるために採取された環境サンプルの3次元的な地理情報(どのような緯度、経度、深度または標高から採取されたサンプルなのか)、環境特性(海水、淡水、土壌、など)、サンプリングサイトに関する物理学的なデータ(気温や気圧、水圧、溶存化学成分、など)、サンプリングの方法論、などに関する詳細情報が含まれる[56]。これらの情報は、メタゲノム解析の再現可能性を確保し、さらなる発展的な解析を可能にするために必要な情報となる。この重要性のため、Genomes OnLine Database(GOLD)などでは、メタデータと付属するデータはレビューとキュレーションを受け、標準化されたデータ形式としてデータベース化されている[57]。
メタデータとシーケンスデータを統合的に管理し解析するために、いくつかのツールが開発されており、異なるデータセットを様々な生態学的指標を使用して比較解析することが可能になっている。例えば2007年、Folker MeyerとRobert Edwards、およびアルゴンヌ国立研究所とシカゴ大学のチームは、メタゲノムデータセット分析のためのコミュニティリソースとしてMetagenomics Rapid Annotation using Subsystem Technology(MG-RAST)サーバをリリースした[58]。このサーバでは2012年6月の時点で8,000人を超えるユーザーが計50,000を超えるメタゲノムプロジェクトの配列を投稿しており、14.8TB(14x1012 bp)を超える配列が分析されている他、10,000を超える公開データセットをMG-RAST内で比較することもできる。また、Integrated Microbial Genomes / Metagenomes(IMG/M)システムは、Integrated Microbial Genomes (IMG)システムおよび Genomic Encyclopedia of Bacteria and Archaea (GEBA)に含まれる単離株のリファレンスゲノムに基づいた、メタゲノム解析による微生物群集機能解析のためのツール群を提供している[59]。
ハイスループットのメタゲノム解析データを分析するために初期に開発されたスタンドアローンなツールの1つはMEGANである[60][61]。このプログラムは、マンモスの骨から得られたメタゲノム配列を分析するために2005年に使用された[62]。このツールはリファレンスゲノムのデータベースとのBLAST検索の結果に基づき、単純な共通祖先(LCA)探索アルゴリズムを使用してリードをNCBI分類のノードに紐付けたり、あるいはリードをSEEDやKEGGの分類ノードに紐付けることにより、系統分類と遺伝子機能の両方を解析することができる[63]。
上述のように今日では、NCBI GenBankのようなゲノム配列データベースは指数関数的に成長している[64]。MG-RASTやMEGANなどのような配列類似性検索ベースのアプローチは、大規模な配列データにアノテーションを付けるには非常に遅く、たとえば中小規模のデータセットに対してでさえ数時間もの実行時間を要してしまうため、より高速で効率的なツールが必要とされており研究が進められている[65]。たとえばCLARKというツールでは、著者らによると「1分あたり3200万のメタゲノムショートリードを分類可能」と宣伝されており、実際に非常に高速に分類アノテーションを実行できる[66]。この速度であれば、10億本のショートリードであっても30分程度で処理できる。
また、古代DNAではそのサンプルの性質上、DNAの損傷に起因する不確実性(シーケンスのエラー等)が大きい。このような不確実性を超えて保守的な配列類似性を推定できるFALCONのようなツールも登場している[67]。著者らによると、メモリと速度のパフォーマンスに影響を与えることなく、緩いしきい値を使用して配列間距離を計算することが可能である。
比較メタゲノム解析
複雑な微生物群集が持つ生理学的な機能やその生息環境との関連を調べる上で、さまざまな異なるメタゲノムデータと比較的に解析することは有用である[68]。メタゲノムデータ間の比較は、配列構成(例えばGC含有量やゲノムサイズの比較)、分類学的多様性(どのような系統の細菌がどのような割合でいるのか)、そして遺伝子機能(どのような機能遺伝子がどのような割合で存在するのか)、といったレベルで行うことができる。群集構造や系統的多様性の比較では、例えば16S rRNAやその他の系統マーカー遺伝子に基づいて行ったり、または多様性の低いコミュニティの場合であればゲノム再構築を経て行うことができる[69]。メタゲノムデータ間の遺伝子機能の比較解析では、例えばCOGやKEGGといった機能遺伝子のリファレンスデータベースを対象に配列類似性検索にかけ、カテゴリ別に相対存在量を集計して統計的に検証することで、データセット間の違いを評価することができる。系統分類類的な解析とは異なり、このような遺伝子ベースの解析では、コミュニティ全体の遺伝子機能の特徴が明らかになる。そして一般には、たとえ別の環境であっても類似した環境条件下であれば、同じような遺伝子機能が分布していることが多い[69](例えば外洋の海洋表層で取られたサンプルであれば、太平洋でも大西洋でも概ね同じような遺伝子機能の分布を示す)。同時にこのことは、メタゲノムサンプルに付随している環境条件に関するメタデータは、コミュニティの構造と機能に対する生息地の影響を研究する上で、非常に重要である[39]。
さらにいくつかの他の研究では、オリゴヌクレオチドの出現パターンを利用して、微生物群集全体の差を比較している。そのような方法論の例には、Willnerらが提唱したジヌクレオチド相対存在量によるアプローチや[70]、Ghoshらが提唱したHabiSignアプローチ[71]がある。後者の研究では、特定のサンプリングサイトを特徴づけるような遺伝子配列(またはメタゲノムリード)を特定するために、テトラヌクレオチドの使用パターンの違いも使用できることを示している。さらにTriageTools[72]やCompareads[73]などの手法では、2つのデータセット間で類似したリードを検出する。この際に使われる類似性の尺度としては、リードのペア間で共有される長さkの配列の数に基づいている。
比較メタゲノム解析の重要な目標の一つは、特定の環境において特定の特性を付与するような、主要な微生物群を特定することである。ただし、これを行う上で、metagenomeSeqというツールで実装されているように、異なるシーケンステクノロジを利用した際のデータバイアスを考慮する必要がある[74]。またいくつかの研究においては、微生物群間の微生物間相互作用を解析している。例えば、Community-Analyzerと呼ばれるGUIベースの比較メタゲノム解析アプリケーションが、Kuntalらによって開発されている[75]。このツールでは相関ベースのグラフアルゴリズムを実装し、系統分類学的な微生物群集構造の違いを視覚化し、さらにそのサンプル固有の微生物間相互作用を推測できる。
発展的・派生的な解析技術
細菌コミュニティにおける代謝
天然の環境や人工的な環境(バイオリアクターなど)下では、多くの細菌のコミュニティで分業的(共生的)な代謝活動を行っており、例えばある生物種が生産する代謝廃棄物が他の生物の代謝産物のベース(餌)になる、というような関係が往々にして見られる[76]。例えばメタン生成バイオリアクターにおいては、その機能的な安定性を確保しつつ原料を完全にメタンに分解するために、いくつかの共生種(SyntrophobacteralesおよびSynergistia)を共存させる必要がある[77]。マイクロアレイなどによる遺伝子研究やプロテオミクスによる遺伝子発現測定を行うことで、種の境界を超えて代謝ネットワークをつなぎ合わせることができる。このような研究では、どのような機能タンパク質がどの系統群、種、株などによって保持されているかについて、詳細な知識が必要となる。そのため、メタゲノム解析から得られるコミュニティのゲノム情報は、メタボロミクスやプロテオミクスによる代謝ネットワーク解析においても、重要な情報となる[78]。
メタトランスクリプトーム解析
メタゲノム解析により、微生物群集の機能的および代謝的な多様性を観測できるが、ゲノム情報からのみでは、どの代謝プロセスが活発に活動しているのか(遺伝子の転写が活発に起きているのか)を示すことはできない[69]。メタゲノム解析と似たような考え方で、細菌コミュニティからmRNAを網羅的に抽出して解析する、いわゆるメタトランスクリプトーム解析(Metatranscriptome)の登場により、コミュニティにおける遺伝子発現のプロファイルを得ることができるようになった[69]。この技術は、最初に土壌中のアンモニア酸化に関する解析に用いられた[79]。一方で、mRNAはDNAに比べて圧倒的に分解されやすいため、環境サンプルからRNAを収集することには様々な技術的困難がある[69]。
ウイルスを対象としたメタゲノム解析(Virome)
メタゲノム解析はバクテリアやアーキアといった原核微生物がターゲットになることが多いが、ウイルス(特にDNA2本鎖ウイルス)に対しても応用することができる。ウイルスには系統間で共通の普遍的なマーカー遺伝子(例えば細菌や古細菌における16S RNAや、真核生物における18S RNAなど)がないため、PCRを介した系統解析が難しい。そのため、環境サンプルからウイルスコミュニティの遺伝的多様性にアクセスする方法として、ウイルスをターゲットとしたメタゲノム解析が有力な方法となっている。このようなウイルスのメタゲノム解析はVirome(日本語ではビローム、ウイローム、ヴァイローム、などと発音される)と呼ばれ、ウイルスの多様性や進化に関して有力な解析手段となっている[80][81][82][83][84]。たとえば、Giant Virus Finderと呼ばれる解析パイプラインでは、塩性砂漠や南極に巨大ウイルスが存在する最初の証拠を示した[85][86]。
メタゲノム解析の応用
メタゲノム解析は、医学や工学、農業、生態学、食品科学などの様々な分野に応用されており、課題解決に役立つ可能性がある[56][87][88]。
農業への応用
植物が成長しているような一般的な土壌には、1グラムあたり109-1010細胞もの微生物が生息している[89][90]。土壌に生息する微生物群集は非常に複雑であるため、農業等で経済的に重要であるにもかかわらず、土壌細菌叢の理解は不十分なままである。土壌中の細菌叢は、大気中の窒素の固定や栄養循環、病気の抑制、シデロフォアによる鉄やその他の金属の隔離など、植物の成長を手助けするさまざまな生態系サービスの役割を担っている。メタゲノム解析により、これらの微生物群集の非培養的な研究を通じて、植物と微生物間の相互作用を解析する研究が進められている[91][92]。メタゲノム解析によるアプローチでは、これまでに培養されていない、あるいは存在量は少ない微生物系統が持つ、栄養循環と植物成長の促進における役割について、有力な情報を提供する可能性がある。このことにより、例えば作物や家畜の感染症の検出や農作物の生育改善といった、農作業プロセスの改善に繋がると考えられている[56]。
バイオ燃料への応用

バイオ燃料とは、トウモロコシの茎やスイッチグラスといったバイオマスに含まれるセルロースを変換し、セルロース系エタノールにして得られる燃料である[56]。この変換プロセスでは、細菌叢の活動によってセルロースが糖に変換され、その後さらに糖がエタノールへと発酵される。また他にも、メタンや水素などのさまざまな生物エネルギー源も微生物が生成することが知られている[56]。
バイオマスを効率的に分解し、産業規模でバイオ燃料を生産するためには、より高い生産性と低コストな新規酵素が必要となる[30]。メタゲノム解析を用いて複雑な微生物群集を解析することで、グリコシド加水分解酵素などのバイオ燃料生産における有用な酵素のスクリーニングが可能になる[93]。また、これらの微生物群集がどのような生態系を営んでいるかを理解することは、その細菌叢を制御する上でために必要であり、メタゲノム解析は有用な解析手法となり得る。メタゲノム解析によって、バイオガス発酵槽[94]やハキリバチの共生真菌[95]といった環境中に生息する細菌叢の比較解析研究が報告されている。
バイオテクノロジーへの応用
微生物群集は、菌叢の内部で繰り広げられる競争とコミュニケーションで使用される、生理学的に活性な化学物質を生産している。今日使用されている薬物の多くは、もともと微生物で発見されたものが多く存在する。そして、未培養系統の微生物が持つ豊富な遺伝資源の探索することで、新しい酵素や天然物及びそれらをコードする遺伝子の発見がなされている[96]。メタゲノム解析の応用により、ファインケミカルの生産や農薬、医薬品等に応用可能な新規遺伝子の探索が進められており、また新規な酵素触媒によるキラル合成なども注目を集めている[91]。
メタゲノム解析をバイオテクノロジーへ応用する際には、大きく分けて2種類の方針がとられる。一つは発現形質に基づく機能駆動型スクリーニングであり、もう一つはDNA配列に基づく配列駆動型スクリーニングである[97]。機能駆動のスクリーニングでは、目的の特性や有用な活性を示すような配列をDNAクローニングと遺伝子発現実験から特定し、続いて生化学的特性評価と配列解析を行う。このアプローチでは、適切なスクリーニングの利用可能性や、求めている形質が宿主細胞で発現されるかどうか、といった要件によって制限される。さらに、一般的にこのアプローチは発見率が低く(1,000もの配列をクローニングしてスクリーニングしても、1配列も当たらないことが往々にしてある)、労働集約的な作業が必要となる[98]。対照的に配列駆動のアプローチでは、既知のDNA配列を使用してPCRプライマーを設計し、目的配列のPCR増幅を配列決定経てスクリーニングを行う[97]。前者のクローニングベースのアプローチと比較して、後者のシーケンスのみのアプローチでは、必要な実験量が大幅に少ない。また、次世代シーケンサーの適用により、膨大な量の配列データを生み出すこともできるが、得られたデータの解析にはバイオインフォマティクス解析が必要になる[98]。配列駆動型アプローチは、配列データベースに含まれる遺伝子機能の量と精度によって制限される。そのため現実的には、目的の機能やスクリーニングするサンプルの複雑さ、およびその他の要因に基づいて、機能駆動形と配列駆動形の両方アプローチを組み合わせて利用することが多い[98][99]。メタゲノム解析から得られた有用物質の例としては、マラシジンという抗生物質などが知られている[100]。
生態学研究への応用
メタゲノム解析は、環境コミュニティが持つ機能生態学に関する貴重な洞察を提供する[101]。例えばオーストラリアのアシカの排便を対象としたメタゲノム解析では、栄養豊富なアシカの糞が、沿岸生態系の栄養源として重要である可能性を示唆している。これは、排便と同時に排出される細菌が、糞中の栄養素を分解し、食物連鎖に組み込みやすい形に変換しているからである[102]。
バイオレメディエーションへの応用
メタゲノム解析は、生態系に対する汚染物質の影響をモニタリングし、汚染された環境を浄化するための戦略の策定に利用できる。具体的には、汚染環境下に生息する微生物群集がどのようにしてその汚染物質に対処するか(代謝的に分解しているのか、あるいは無力化しているのか、など)を解明することで、汚染環境の評価方法を向上させたり、生物的な汚染物質の除去、すなわちバイオレメディエーションの技術開発に繋がると考えられている[103]。
ヒト常在細菌叢への応用
腸内細菌を含むヒト常在菌は、健康を維持する上で重要な役割を果たしていると考えられているが、その菌叢構造や生態学的メカニズムは十分には分かっておらず様々な人種や体組織において、メタゲノム解析による大規模なシーケンス研究が進められている。例えばHuman Microbiomeプロジェクトでは、250人以上の個人の15〜18の身体部位について解析がなされている。このプロジェクトでは、ヒトの健康と相関する可能性のあるヒトマイクロバイオームを理解し、その目標のために必要となる新しい実験的およびバイオインフォマティクス技術を開発するということを目標としている[103]。
また別のプロジェクトであるMetaHit(Metagenomics of the Human Intestinal Tract、ヒト腸管のメタゲノミクス)の一部として行われた研究は、健常者や肥満者、過敏性腸疾患患者などからなる124人のデンマークとスペインの個人を解析している。この研究は、胃腸に生息する細菌叢がどのような系統的多様性を持つのかに関して調べている。その結果、バクテロイデス(Bacteroidetes)とファーミキューテス(Firmicutes)の2つの細菌門が、腸内細菌叢の90%以上を構成する系統群であるということを実証した。また、メタゲノム解析から得られた遺伝子配列の出現頻度を利用して、腸管の健康にとって重要な可能性がある1,244個の遺伝子クラスターを特定した。このクラスターには、ハウスキーピング遺伝子の他に、腸特有の機能を持つ遺伝子の2タイプが含まれていた。前者はあらゆる細菌に必須なハウスキーピング遺伝子から構成されており、炭素代謝やアミノ酸合成などの主要な代謝経路に関連した機能を持っていた。一方で後者の腸特有の機能には、宿主タンパク質への接着やグロボシリーズ糖脂質からの糖生成に関する機能が見られた。過敏性腸症候群の患者は、健常者と比較して菌叢中の遺伝子と系統多様性が25%低く、腸内細菌叢の多様性の変化がこの疾患状態に関連している可能性が示唆された。この研究では、いくつかの潜在的に価値のある医学的応用が強調されているている。しかしながら、リード全体では31–48.8%程度のリードしか194の既知のヒト腸内細菌ゲノムにマップされず、7.6–21.2%のゲノムしかGenBankで利用可能な細菌ゲノムと整合していなかったため、さらなる未解読の新規細菌ゲノムを明らかにしていく研究を進めていく必要があることが示唆された[104]。
感染症診断への応用
感染症を診断し、その感染の根底にある病因を特定することは、困難であることが多い。例えば脳炎の症例の半数以上は、最先端の臨床検査法を用いた広範な検査であっても診断がつかないことがある。メタゲノム解析では、患者のサンプルに含まれる遺伝物質を、何千もの細菌、ウイルス、その他の病原体のゲノムデータが含まれたデータベースと比較することで、高感度に感染の診断を行うことができるため、診断手法として応用が期待されている。
脚注
- ^ 木暮(2011), 「海洋における環境ゲノミクス」『地球環境』 Vol.16 No.1 p,71-79, NAID 40018854028
- ^ 工藤俊章 『難培養微生物の利用技術』 シーエムシー出版、2010年、はじめに
- ^ Eisen, Jonathan A (2007-03-13). Simon Levin. ed. “Environmental Shotgun Sequencing: Its Potential and Challenges for Studying the Hidden World of Microbes” (英語). PLoS Biology 5 (3): e82. doi:10.1371/journal.pbio.0050082. ISSN 1545-7885. PMC 1821061. PMID 17355177.
- ^ Rausch, Philipp; Rühlemann, Malte; Hermes, Britt M.; Doms, Shauni; Dagan, Tal; Dierking, Katja; Domin, Hanna; Fraune, Sebastian et al. (2019-12). “Comparative analysis of amplicon and metagenomic sequencing methods reveals key features in the evolution of animal metaorganisms” (英語). Microbiome 7 (1): 133. doi:10.1186/s40168-019-0743-1. ISSN 2049-2618. PMC 6744666. PMID 31521200.
- ^ “イルミナ「総説:メタゲノム研究」”. 2020年3月23日閲覧。
- ^ 今すぐ始める! メタゲノム解析 実験プロトコール. Hattori, masahira., 服部, 正平. 羊土社. (2016). ISBN 978-4-7581-0197-4. OCLC 1089711913
- ^ a b Handelsman, J.; Rondon, M. R.; Brady, S. F.; Clardy, J.; Goodman, R. M. (1998-10). “Molecular biological access to the chemistry of unknown soil microbes: a new frontier for natural products”. Chemistry & Biology 5 (10): R245–249. doi:10.1016/s1074-5521(98)90108-9. ISSN 1074-5521. PMID 9818143.
- ^ Chen, K.; Pachter, L. (2005). "Bioinformatics for Whole-Genome Shotgun Sequencing of Microbial Communities". PLoS Computational Biology 1 (2): e24. doi:10.1371/journal.pcbi.0010024
- ^ Hugenholz, P; Goebel BM; Pace NR (1 September 1998). "Impact of Culture-Independent Studies on the Emerging Phylogenetic View of Bacterial Diversity". J. Bacteriol 180(18): 4765–74. PMC 107498.PMID 9733676
- ^ Lane, D. J.; Pace, B.; Olsen, G. J.; Stahl, D. A.; Sogin, M. L.; Pace, N. R. (1985-10). “Rapid determination of 16S ribosomal RNA sequences for phylogenetic analyses”. Proceedings of the National Academy of Sciences of the United States of America 82 (20): 6955–6959. doi:10.1073/pnas.82.20.6955. ISSN 0027-8424. PMC 391288. PMID 2413450.
- ^ Pace, Norman R.; Stahl, David A.; Lane, David J.; Olsen, Gary J. (1986). Marshall, K. C.. ed (英語). Advances in Microbial Ecology. Boston, MA: Springer US. pp. 1–55. doi:10.1007/978-1-4757-0611-6_1. ISBN 978-1-4757-0611-6
- ^ Schmidt, T M; DeLong, E F; Pace, N R (1991). “Analysis of a marine picoplankton community by 16S rRNA gene cloning and sequencing.” (英語). Journal of Bacteriology 173 (14): 4371–4378. doi:10.1128/JB.173.14.4371-4378.1991. ISSN 0021-9193. PMC 208098. PMID 2066334.
- ^ Healy, F. G.; Ray, R. M.; Aldrich, H. C.; Wilkie, A. C.; Ingram, L. O.; Shanmugam, K. T. (1995-09). “Direct isolation of functional genes encoding cellulases from the microbial consortia in a thermophilic, anaerobic digester maintained on lignocellulose” (英語). Applied Microbiology and Biotechnology 43 (4): 667–674. doi:10.1007/BF00164771. ISSN 0175-7598.
- ^ Stein, J L; Marsh, T L; Wu, K Y; Shizuya, H; DeLong, E F (1996). “Characterization of uncultivated prokaryotes: isolation and analysis of a 40-kilobase-pair genome fragment from a planktonic marine archaeon.” (英語). Journal of bacteriology 178 (3): 591–599. doi:10.1128/JB.178.3.591-599.1996. ISSN 0021-9193. PMC 177699. PMID 8550487.
- ^ Breitbart, M.; Salamon, P.; Andresen, B.; Mahaffy, J. M.; Segall, A. M.; Mead, D.; Azam, F.; Rohwer, F. (2002-10-29). “Genomic analysis of uncultured marine viral communities” (英語). Proceedings of the National Academy of Sciences 99 (22): 14250–14255. doi:10.1073/pnas.202488399. ISSN 0027-8424. PMC PMC137870. PMID 12384570.
- ^ a b Tyson, Gene W.; Chapman, Jarrod; Hugenholtz, Philip; Allen, Eric E.; Ram, Rachna J.; Richardson, Paul M.; Solovyev, Victor V.; Rubin, Edward M. et al. (2004-03). “Community structure and metabolism through reconstruction of microbial genomes from the environment” (英語). Nature 428 (6978): 37–43. doi:10.1038/nature02340. ISSN 0028-0836.
- ^ Venter, J. C. (2004-04-02). “Environmental Genome Shotgun Sequencing of the Sargasso Sea” (英語). Science 304 (5667): 66–74. doi:10.1126/science.1093857. ISSN 0036-8075.
- ^ Yooseph, Shibu; Nealson, Kenneth H.; Rusch, Douglas B.; McCrow, John P.; Dupont, Christopher L.; Kim, Maria; Johnson, Justin; Montgomery, Robert et al. (2010-11). “Genomic and functional adaptation in surface ocean planktonic prokaryotes” (英語). Nature 468 (7320): 60–66. doi:10.1038/nature09530. ISSN 0028-0836.
- ^ Poinar, Hendrik N.; Schwarz, Carsten; Qi, Ji; Shapiro, Beth; MacPhee, Ross D. E.; Buigues, Bernard; Tikhonov, Alexei; Huson, Daniel H. et al. (2006-01-20). “Metagenomics to Paleogenomics: Large-Scale Sequencing of Mammoth DNA” (英語). Science 311 (5759): 392–394. doi:10.1126/science.1123360. ISSN 0036-8075.
- ^ Edwards, Robert A; Rodriguez-Brito, Beltran; Wegley, Linda; Haynes, Matthew; Breitbart, Mya; Peterson, Dean M; Saar, Martin O; Alexander, Scott et al. (2006-12). “Using pyrosequencing to shed light on deep mine microbial ecology” (英語). BMC Genomics 7 (1): 57. doi:10.1186/1471-2164-7-57. ISSN 1471-2164. PMC 1483832. PMID 16549033.
- ^ Jiang, Bai; Song, Kai; Ren, Jie; Deng, Minghua; Sun, Fengzhu; Zhang, Xuegong (2012). “Comparison of metagenomic samples using sequence signatures” (英語). BMC Genomics 13 (1): 730. doi:10.1186/1471-2164-13-730. ISSN 1471-2164. PMC PMC3549735. PMID 23268604.
- ^ 服部正平; 林哲也; 黒川顕; 伊藤武彦; 桑原知巳『ヒト腸内細菌叢のゲノムシークエンス』公益財団法人 腸内細菌学会、2007年。doi:10.11209/jim.21.187。2020年5月25日閲覧。
- ^ Poinar, Hendrik N.; Schwarz, Carsten; Qi, Ji; Shapiro, Beth; MacPhee, Ross D. E.; Buigues, Bernard; Tikhonov, Alexei; Huson, Daniel H. et al. (2006-01-20). “Metagenomics to Paleogenomics: Large-Scale Sequencing of Mammoth DNA” (英語). Science 311 (5759): 392–394. doi:10.1126/science.1123360. ISSN 0036-8075.
- ^ Rodrigue, Sébastien; Materna, Arne C.; Timberlake, Sonia C.; Blackburn, Matthew C.; Malmstrom, Rex R.; Alm, Eric J.; Chisholm, Sallie W. (2010-07-28). Gilbert, Jack Anthony. ed. “Unlocking Short Read Sequencing for Metagenomics” (英語). PLoS ONE 5 (7): e11840. doi:10.1371/journal.pone.0011840. ISSN 1932-6203. PMC 2911387. PMID 20676378.
- ^ Schuster, Stephan C (2008-01). “Next-generation sequencing transforms today's biology” (英語). Nature Methods 5 (1): 16–18. doi:10.1038/nmeth1156. ISSN 1548-7091.
- ^ “Metagenomics versus Moore's law” (英語). Nature Methods 6 (9): 623–623. (2009-09). doi:10.1038/nmeth0909-623. ISSN 1548-7091.
- ^ a b Hiraoka, Satoshi; Yang, Ching-chia; Iwasaki, Wataru (2016). “Metagenomics and Bioinformatics in Microbial Ecology: Current Status and Beyond” (英語). Microbes and environments 31 (3): 204–212. doi:10.1264/jsme2.ME16024. ISSN 1342-6311. PMC 5017796. PMID 27383682.
- ^ Watson, Mick; Roehe, Rainer; Walker, Alan W.; Dewhurst, Richard J.; Snelling, Timothy J.; Ivan Liachko; Langford, Kyle W.; Press, Maximilian O. et al. (28 February 2018). “Assembly of 913 microbial genomes from metagenomic sequencing of the cow rumen” (英語). Nature Communications 9 (1): 870. Bibcode: 2018NatCo...9..870S. doi:10.1038/s41467-018-03317-6. ISSN 2041-1723. PMC 5830445. PMID 29491419.
- ^ Thomas, T.; Gilbert, J.; Meyer, F. (2012). “Metagenomics - a guide from sampling to data analysis”. Microbial Informatics and Experimentation 2 (1): 3. doi:10.1186/2042-5783-2-3. PMC 3351745. PMID 22587947.
- ^ a b Hess, M.; Sczyrba, A.; Egan, R.; Kim, T.-W.; Chokhawala, H.; Schroth, G.; Luo, S.; Clark, D. S. et al. (2011-01-28). “Metagenomic Discovery of Biomass-Degrading Genes and Genomes from Cow Rumen” (英語). Science 331 (6016): 463–467. doi:10.1126/science.1200387. ISSN 0036-8075.
- ^ MetaHIT Consortium; Qin, Junjie; Li, Ruiqiang; Raes, Jeroen; Arumugam, Manimozhiyan; Burgdorf, Kristoffer Solvsten; Manichanh, Chaysavanh; Nielsen, Trine et al. (2010-03). “A human gut microbial gene catalogue established by metagenomic sequencing” (英語). Nature 464 (7285): 59–65. doi:10.1038/nature08821. ISSN 0028-0836. PMC 3779803. PMID 20203603.
- ^ Oulas, A; Pavloudi, C; Polymenakou, P; Pavlopoulos, GA; Papanikolaou, N; Kotoulas, G; Arvanitidis, C; Iliopoulos, I (2015). “Metagenomics: tools and insights for analyzing next-generation sequencing data derived from biodiversity studies”. Bioinformatics and Biology Insights 9: 75–88. doi:10.4137/BBI.S12462. PMC 4426941. PMID 25983555.
- ^ Mende, Daniel R.; Alison S. Waller; Shinichi Sunagawa; Aino I. Järvelin; Michelle M. Chan; Manimozhiyan Arumugam; Jeroen Raes; Peer Bork (23 February 2012). “Assessment of Metagenomic Assembly Using Simulated Next Generation Sequencing Data”. PLoS ONE 7 (2): e31386. Bibcode: 2012PLoSO...731386M. doi:10.1371/journal.pone.0031386. ISSN 1932-6203. PMC 3285633. PMID 22384016.
- ^ Balzer, S.; Malde, K.; Grohme, M. A.; Jonassen, I. (2013). “Filtering duplicate reads from 454 pyrosequencing data”. Bioinformatics 29 (7): 830–836. doi:10.1093/bioinformatics/btt047. PMC 3605598. PMID 23376350.
- ^ Mohammed, MH; Sudha Chadaram; Dinakar Komanduri; Tarini Shankar Ghosh; Sharmila S Mande (2011). “Eu-Detect: an algorithm for detecting eukaryotic sequences in metagenomic data sets”. Journal of Biosciences 36 (4): 709–717. doi:10.1007/s12038-011-9105-2. PMID 21857117.
- ^ R, Schmeider; R Edwards (2011). “Fast identification and removal of sequence contamination from genomic and metagenomic datasets”. PLoS ONE 6 (3): e17288. Bibcode: 2011PLoSO...617288S. doi:10.1371/journal.pone.0017288. PMC 3052304. PMID 21408061.
- ^ a b c Kunin, V.; Copeland, A.; Lapidus, A.; Mavromatis, K.; Hugenholtz, P. (2008-12-01). “A Bioinformatician's Guide to Metagenomics” (英語). Microbiology and Molecular Biology Reviews 72 (4): 557–578. doi:10.1128/MMBR.00009-08. ISSN 1092-2172. PMC PMC2593568. PMID 19052320.
- ^ Burton, Joshua N.; Liachko, Ivan; Dunham, Maitreya J.; Shendure, Jay (2014-07). “Species-Level Deconvolution of Metagenome Assemblies with Hi-C–Based Contact Probability Maps” (英語). G3: Genes|Genomes|Genetics 4 (7): 1339–1346. doi:10.1534/g3.114.011825. ISSN 2160-1836. PMC 4455782. PMID 24855317.
- ^ a b Wooley, John C.; Godzik, Adam; Friedberg, Iddo (2010-02-26). Bourne, Philip E.. ed. “A Primer on Metagenomics” (英語). PLoS Computational Biology 6 (2): e1000667. doi:10.1371/journal.pcbi.1000667. ISSN 1553-7358. PMC 2829047. PMID 20195499.
- ^ Zerbino, D. R.; Birney, E. (2008-02-21). “Velvet: Algorithms for de novo short read assembly using de Bruijn graphs” (英語). Genome Research 18 (5): 821–829. doi:10.1101/gr.074492.107. ISSN 1088-9051. PMC 2336801. PMID 18349386.
- ^ Namiki, Toshiaki; Hachiya, Tsuyoshi; Tanaka, Hideaki; Sakakibara, Yasubumi (2012-11-01). “MetaVelvet: an extension of Velvet assembler to de novo metagenome assembly from short sequence reads” (英語). Nucleic Acids Research 40 (20): e155–e155. doi:10.1093/nar/gks678. ISSN 1362-4962. PMC 3488206. PMID 22821567.
- ^ Burton, Joshua N.; Liachko, Ivan; Dunham, Maitreya J.; Shendure, Jay (2014-07). “Species-Level Deconvolution of Metagenome Assemblies with Hi-C–Based Contact Probability Maps” (英語). G3: Genes|Genomes|Genetics 4 (7): 1339–1346. doi:10.1534/g3.114.011825. ISSN 2160-1836. PMC 4455782. PMID 24855317.
- ^ Huson, D. H.; Mitra, S.; Ruscheweyh, H.-J.; Weber, N.; Schuster, S. C. (2011-09-01). “Integrative analysis of environmental sequences using MEGAN4” (英語). Genome Research 21 (9): 1552–1560. doi:10.1101/gr.120618.111. ISSN 1088-9051. PMC 3166839. PMID 21690186.
- ^ Zhu, Wenhan; Lomsadze, Alexandre; Borodovsky, Mark (2010-07). “Ab initio gene identification in metagenomic sequences” (英語). Nucleic Acids Research 38 (12): e132–e132. doi:10.1093/nar/gkq275. ISSN 1362-4962. PMC 2896542. PMID 20403810.
- ^ Wooley, John C.; Godzik, Adam; Friedberg, Iddo (2010-02-26). Bourne, Philip E.. ed. “A Primer on Metagenomics” (英語). PLoS Computational Biology 6 (2): e1000667. doi:10.1371/journal.pcbi.1000667. ISSN 1553-7358. PMC 2829047. PMID 20195499.
- ^ Hug, Laura A.; Baker, Brett J.; Anantharaman, Karthik; Brown, Christopher T.; Probst, Alexander J.; Castelle, Cindy J.; Butterfield, Cristina N.; Hernsdorf, Alex W. et al. (11 April 2016). “A new view of the tree of life”. Nature Microbiology 1 (5): 16048. doi:10.1038/nmicrobiol.2016.48. PMID 27572647.
- ^ Konopka, Allan (2009-11). “What is microbial community ecology?” (英語). The ISME Journal 3 (11): 1223–1230. doi:10.1038/ismej.2009.88. ISSN 1751-7362.
- ^ Huson, D. H.; Auch, A. F.; Qi, J.; Schuster, S. C. (2007-02-06). “MEGAN analysis of metagenomic data” (英語). Genome Research 17 (3): 377–386. doi:10.1101/gr.5969107. ISSN 1088-9051. PMC 1800929. PMID 17255551.
- ^ Segata, Nicola; Waldron, Levi; Ballarini, Annalisa; Narasimhan, Vagheesh; Jousson, Olivier; Huttenhower, Curtis (2012-08). “Metagenomic microbial community profiling using unique clade-specific marker genes” (英語). Nature Methods 9 (8): 811–814. doi:10.1038/nmeth.2066. ISSN 1548-7091. PMC 3443552. PMID 22688413.
- ^ Liu, Bo; Gibbons, Theodore; Ghodsi, Mohammad; Treangen, Todd; Pop, Mihai (2011). “Accurate and fast estimation of taxonomic profiles from metagenomic shotgun sequences” (英語). BMC Genomics 12 (Suppl 2): S4. doi:10.1186/1471-2164-12-S2-S4. ISSN 1471-2164. PMC 3194235. PMID 21989143.
- ^ Milanese, Alessio; Mende, Daniel R; Paoli, Lucas; Salazar, Guillem; Ruscheweyh, Hans-Joachim; Cuenca, Miguelangel; Hingamp, Pascal; Alves, Renato et al. (2019-12). “Microbial abundance, activity and population genomic profiling with mOTUs2” (英語). Nature Communications 10 (1): 1014. doi:10.1038/s41467-019-08844-4. ISSN 2041-1723. PMC 6399450. PMID 30833550.
- ^ Liu, Bo; Gibbons, Theodore; Ghodsi, Mohammad; Treangen, Todd; Pop, Mihai (2011). “Accurate and fast estimation of taxonomic profiles from metagenomic shotgun sequences” (英語). BMC Genomics 12 (Suppl 2): S4. doi:10.1186/1471-2164-12-S2-S4. ISSN 1471-2164. PMC 3194235. PMID 21989143.
- ^ Milanese, Alessio; Mende, Daniel R; Paoli, Lucas; Salazar, Guillem; Ruscheweyh, Hans-Joachim; Cuenca, Miguelangel; Hingamp, Pascal; Alves, Renato et al. (2019-12). “Microbial abundance, activity and population genomic profiling with mOTUs2” (英語). Nature Communications 10 (1): 1014. doi:10.1038/s41467-019-08844-4. ISSN 2041-1723. PMC 6399450. PMID 30833550.
- ^ Dadi, Temesgen Hailemariam; Renard, Bernhard Y.; Wieler, Lothar H.; Semmler, Torsten; Reinert, Knut (2017-03-28). “SLIMM: species level identification of microorganisms from metagenomes” (英語). PeerJ 5: e3138. doi:10.7717/peerj.3138. ISSN 2167-8359. PMC 5372838. PMID 28367376.
- ^ Wooley, John C.; Godzik, Adam; Friedberg, Iddo (2010-02-26). Bourne, Philip E.. ed. “A Primer on Metagenomics” (英語). PLoS Computational Biology 6 (2): e1000667. doi:10.1371/journal.pcbi.1000667. ISSN 1553-7358. PMC 2829047. PMID 20195499.
- ^ a b c d e The New Science of Metagenomics: Revealing the Secrets of Our Microbial Planet. Washington, D.C.: National Academies Press. (2007-05-24). doi:10.17226/11902. ISBN 978-0-309-10676-4
- ^ Pagani, I.; Liolios, K.; Jansson, J.; Chen, I.-M. A.; Smirnova, T.; Nosrat, B.; Markowitz, V. M.; Kyrpides, N. C. (2012-01-01). “The Genomes OnLine Database (GOLD) v.4: status of genomic and metagenomic projects and their associated metadata” (英語). Nucleic Acids Research 40 (D1): D571–D579. doi:10.1093/nar/gkr1100. ISSN 0305-1048. PMC 3245063. PMID 22135293.
- ^ Meyer, F; Paarmann, D; D'Souza, M; Olson, R; Glass, Em; Kubal, M; Paczian, T; Rodriguez, A et al. (2008-12). “The metagenomics RAST server – a public resource for the automatic phylogenetic and functional analysis of metagenomes” (英語). BMC Bioinformatics 9 (1): 386. doi:10.1186/1471-2105-9-386. ISSN 1471-2105. PMC 2563014. PMID 18803844.
- ^ Markowitz, V. M.; Chen, I.-M. A.; Chu, K.; Szeto, E.; Palaniappan, K.; Grechkin, Y.; Ratner, A.; Jacob, B. et al. (2012-01-01). “IMG/M: the integrated metagenome data management and comparative analysis system” (英語). Nucleic Acids Research 40 (D1): D123–D129. doi:10.1093/nar/gkr975. ISSN 0305-1048. PMC 3245048. PMID 22086953.
- ^ Huson, D. H.; Mitra, S.; Ruscheweyh, H.-J.; Weber, N.; Schuster, S. C. (2011-09-01). “Integrative analysis of environmental sequences using MEGAN4” (英語). Genome Research 21 (9): 1552–1560. doi:10.1101/gr.120618.111. ISSN 1088-9051. PMC 3166839. PMID 21690186.
- ^ Huson, D. H.; Auch, A. F.; Qi, J.; Schuster, S. C. (2007-02-06). “MEGAN analysis of metagenomic data” (英語). Genome Research 17 (3): 377–386. doi:10.1101/gr.5969107. ISSN 1088-9051. PMC 1800929. PMID 17255551.
- ^ Poinar, Hendrik N.; Schwarz, Carsten; Qi, Ji; Shapiro, Beth; MacPhee, Ross D. E.; Buigues, Bernard; Tikhonov, Alexei; Huson, Daniel H. et al. (2006-01-20). “Metagenomics to Paleogenomics: Large-Scale Sequencing of Mammoth DNA” (英語). Science 311 (5759): 392–394. doi:10.1126/science.1123360. ISSN 0036-8075.
- ^ Mitra, Suparna; Rupek, Paul; Richter, Daniel C; Urich, Tim; Gilbert, Jack A; Meyer, Folker; Wilke, Andreas; Huson, Daniel H (2011-12). “Functional analysis of metagenomes and metatranscriptomes using SEED and KEGG” (英語). BMC Bioinformatics 12 (S1): S21. doi:10.1186/1471-2105-12-S1-S21. ISSN 1471-2105. PMC 3044276. PMID 21342551.
- ^ Benson, Dennis A.; Cavanaugh, Mark; Clark, Karen; Karsch-Mizrachi, Ilene; Lipman, David J.; Ostell, James; Sayers, Eric W. (2012-11-26). “GenBank” (英語). Nucleic Acids Research 41 (D1): D36–D42. doi:10.1093/nar/gks1195. ISSN 0305-1048. PMC 3531190. PMID 23193287.
- ^ Bazinet, Adam L; Cummings, Michael P (2012-12). “A comparative evaluation of sequence classification programs” (英語). BMC Bioinformatics 13 (1): 92. doi:10.1186/1471-2105-13-92. ISSN 1471-2105. PMC 3428669. PMID 22574964.
- ^ Ounit, Rachid; Wanamaker, Steve; Close, Timothy J; Lonardi, Stefano (2015-12). “CLARK: fast and accurate classification of metagenomic and genomic sequences using discriminative k-mers” (英語). BMC Genomics 16 (1): 236. doi:10.1186/s12864-015-1419-2. ISSN 1471-2164. PMC 4428112. PMID 25879410.
- ^ Pratas, Diogo; Hosseini, Morteza; Grilo, Gonçalo; Pinho, Armando; Silva, Raquel; Caetano, Tânia; Carneiro, João; Pereira, Filipe (2018-09-06). “Metagenomic Composition Analysis of an Ancient Sequenced Polar Bear Jawbone from Svalbard” (英語). Genes 9 (9): 445. doi:10.3390/genes9090445. ISSN 2073-4425. PMC 6162538. PMID 30200636.
- ^ Kurokawa, Ken; Itoh, Takehiko; Kuwahara, Tomomi; Oshima, Kenshiro; Toh, Hidehiro; Toyoda, Atsushi; Takami, Hideto; Morita, Hidetoshi et al. (2007). “Comparative Metagenomics Revealed Commonly Enriched Gene Sets in Human Gut Microbiomes” (英語). DNA Research 14 (4): 169–181. doi:10.1093/dnares/dsm018. ISSN 1756-1663. PMC 2533590. PMID 17916580.
- ^ a b c d e Simon, Carola; Daniel, Rolf (2011-02-15). “Metagenomic Analyses: Past and Future Trends” (英語). Applied and Environmental Microbiology 77 (4): 1153–1161. doi:10.1128/AEM.02345-10. ISSN 0099-2240. PMC PMC3067235. PMID 21169428.
- ^ Willner, D; RV Thurber; F Rohwer (2009). “Metagenomic signatures of 86 microbial and viral metagenomes.”. Environmental Microbiology 11 (7): 1752–66. doi:10.1111/j.1462-2920.2009.01901.x. PMID 19302541.
- ^ Ghosh, Tarini Shankar; Monzoorul Haque Mohammed; Hannah Rajasingh; Sudha Chadaram; Sharmila S Mande (2011). “HabiSign: a novel approach for comparison of metagenomes and rapid identification of habitat-specific sequences.”. BMC Bioinformatics 12 (Supplement 13): S9. doi:10.1186/1471-2105-12-s13-s9. PMC 3278849. PMID 22373355.
- ^ Fimereli, Danai; Detours, Vincent; Konopka, Tomasz (2013-04-01). “TriageTools: tools for partitioning and prioritizing analysis of high-throughput sequencing data” (英語). Nucleic Acids Research 41 (7): e86–e86. doi:10.1093/nar/gkt094. ISSN 1362-4962. PMC 3627586. PMID 23408855.
- ^ Maillet, Nicolas; Lemaitre, Claire; Chikhi, Rayan; Lavenier, Dominique; Peterlongo, Pierre (2012-12). “Compareads: comparing huge metagenomic experiments” (英語). BMC Bioinformatics 13 (S19): S10. doi:10.1186/1471-2105-13-S19-S10. ISSN 1471-2105. PMC 3526429. PMID 23282463.
- ^ Paulson, Joseph N; Stine, O Colin; Bravo, Héctor Corrada; Pop, Mihai (2013-12). “Differential abundance analysis for microbial marker-gene surveys” (英語). Nature Methods 10 (12): 1200–1202. doi:10.1038/nmeth.2658. ISSN 1548-7091. PMC 4010126. PMID 24076764.
- ^ Bhusan, Kuntal Kumar; Tarini Shankar Ghosh; Sharmila S Mande (2013). “Community-analyzer: a platform for visualizing and comparing microbial community structure across microbiomes”. Genomics 102 (4): 409–418. doi:10.1016/j.ygeno.2013.08.004. PMID 23978768.
- ^ Werner, J. J.; Knights, D.; Garcia, M. L.; Scalfone, N. B.; Smith, S.; Yarasheski, K.; Cummings, T. A.; Beers, A. R. et al. (2011-03-08). “Bacterial community structures are unique and resilient in full-scale bioenergy systems” (英語). Proceedings of the National Academy of Sciences 108 (10): 4158–4163. doi:10.1073/pnas.1015676108. ISSN 0027-8424. PMC 3053989. PMID 21368115.
- ^ McInerney, Michael J; Sieber, Jessica R; Gunsalus, Robert P (2009-12). “Syntrophy in anaerobic global carbon cycles” (英語). Current Opinion in Biotechnology 20 (6): 623–632. doi:10.1016/j.copbio.2009.10.001. PMC 2790021. PMID 19897353.
- ^ Klitgord, Niels; Segrè, Daniel (2011-08). “Ecosystems biology of microbial metabolism” (英語). Current Opinion in Biotechnology 22 (4): 541–546. doi:10.1016/j.copbio.2011.04.018.
- ^ Leininger, S.; Urich, T.; Schloter, M.; Schwark, L.; Qi, J.; Nicol, G. W.; Prosser, J. I.; Schuster, S. C. et al. (2006-08). “Archaea predominate among ammonia-oxidizing prokaryotes in soils” (英語). Nature 442 (7104): 806–809. doi:10.1038/nature04983. ISSN 0028-0836.
- ^ “Uncovering Earth's virome”. Nature 536 (7617): 425–30. (August 2016). Bibcode: 2016Natur.536..425P. doi:10.1038/nature19094. PMID 27533034.
- ^ “IMG/VR: a database of cultured and uncultured DNA Viruses and retroviruses”. Nucleic Acids Research 45 (D1): D457-D465. (January 2017). doi:10.1093/nar/gkw1030. PMC 5210529. PMID 27799466.
- ^ “IMG/VR v.2.0: an integrated data management and analysis system for cultivated and environmental viral genomes”. Nucleic Acids Research 47 (D1): D678-D686. (January 2019). doi:10.1093/nar/gky1127. PMC 6323928. PMID 30407573.
- ^ Paez-Espino, David; Pavlopoulos, Georgios A; Ivanova, Natalia N; Kyrpides, Nikos C (2017-08). “Nontargeted virus sequence discovery pipeline and virus clustering for metagenomic data” (英語). Nature Protocols 12 (8): 1673–1682. doi:10.1038/nprot.2017.063. ISSN 1754-2189.
- ^ Kristensen, David M.; Mushegian, Arcady R.; Dolja, Valerian V.; Koonin, Eugene V. (2010-01). “New dimensions of the virus world discovered through metagenomics” (英語). Trends in Microbiology 18 (1): 11–19. doi:10.1016/j.tim.2009.11.003. PMC PMC3293453. PMID 19942437.
- ^ “Giant viruses of the Kutch Desert”. Archives of Virology 161 (3): 721–4. (March 2016). arXiv:1410.1278. doi:10.1007/s00705-015-2720-8. PMID 26666442.
- ^ “The "Giant Virus Finder" discovers an abundance of giant viruses in the Antarctic dry valleys”. Archives of Virology 162 (6): 1671–1676. (June 2017). arXiv:1503.05575. doi:10.1007/s00705-017-3286-4. PMID 28247094.
- ^ “The World Within Us”. Healthcare Journal of New Orleans: 21-26. (Sep-Oct 2017).
- ^ Kusumoto, Ken-Ichi「Metagenomic Analysis」『Nippon Shokuhin Kagaku Kogaku Kaishi』第58巻第3号、2011年、136–136頁、doi:10.3136/nskkk.58.136、ISSN 1341-027X。
- ^ Jansson, Janet (2011-01-01). “Towards “Tera-Terra”: Terabase Sequencing of Terrestrial Metagenomes: Microbial ecologists are taking a metagenomics approach to analyze complex and diverse soil microbial communities” (英語). Microbe Magazine 6 (7): 309–315. doi:10.1128/microbe.6.309.1. ISSN 1558-7452.
- ^ Vogel, Timothy M.; Simonet, Pascal; Jansson, Janet K.; Hirsch, Penny R.; Tiedje, James M.; van Elsas, Jan Dirk; Bailey, Mark J.; Nalin, Renaud et al. (2009-04). “TerraGenome: a consortium for the sequencing of a soil metagenome” (英語). Nature Reviews Microbiology 7 (4): 252–252. doi:10.1038/nrmicro2119. ISSN 1740-1526.
- ^ a b Metagenomics : theory, methods, and applications. Marco, Diana.. Wymondham: Caister Academic Press. (2010). ISBN 978-1-904455-54-7. OCLC 351318426
- ^ “Pivotal roles of phyllosphere microorganisms at the interface between plant functioning and atmospheric trace gas dynamics”. Frontiers in Microbiology 6: 486. (22 May 2015). doi:10.3389/fmicb.2015.00486. PMC 4440916. PMID 26052316.
- ^ Li, Luen-Luen; McCorkle, Sean R; Monchy, Sebastien; Taghavi, Safiyh; van der Lelie, Daniel (2009). “Bioprospecting metagenomes: glycosyl hydrolases for converting biomass” (英語). Biotechnology for Biofuels 2 (1): 10. doi:10.1186/1754-6834-2-10. ISSN 1754-6834. PMC 2694162. PMID 19450243.
- ^ Jaenicke, Sebastian; Ander, Christina; Bekel, Thomas; Bisdorf, Regina; Dröge, Marcus; Gartemann, Karl-Heinz; Jünemann, Sebastian; Kaiser, Olaf et al. (2011-01-26). Aziz, Ramy K.. ed. “Comparative and Joint Analysis of Two Metagenomic Datasets from a Biogas Fermenter Obtained by 454-Pyrosequencing” (英語). PLoS ONE 6 (1): e14519. doi:10.1371/journal.pone.0014519. ISSN 1932-6203. PMC 3027613. PMID 21297863.
- ^ Suen, Garret; Scott, Jarrod J.; Aylward, Frank O.; Adams, Sandra M.; Tringe, Susannah G.; Pinto-Tomás, Adrián A.; Foster, Clifton E.; Pauly, Markus et al. (2010-09-23). Sonnenburg, Justin. ed. “An Insect Herbivore Microbiome with High Plant Biomass-Degrading Capacity” (英語). PLoS Genetics 6 (9): e1001129. doi:10.1371/journal.pgen.1001129. ISSN 1553-7404. PMC 2944797. PMID 20885794.
- ^ Simon, Carola; Daniel, Rolf (2009-11). “Achievements and new knowledge unraveled by metagenomic approaches” (英語). Applied Microbiology and Biotechnology 85 (2): 265–276. doi:10.1007/s00253-009-2233-z. ISSN 0175-7598. PMC 2773367. PMID 19760178.
- ^ a b Schloss, Patrick D; Handelsman, Jo (2003-06). “Biotechnological prospects from metagenomics” (英語). Current Opinion in Biotechnology 14 (3): 303–310. doi:10.1016/S0958-1669(03)00067-3.
- ^ a b c Kakirde, Kavita S.; Parsley, Larissa C.; Liles, Mark R. (2010-11). “Size does matter: Application-driven approaches for soil metagenomics” (英語). Soil Biology and Biochemistry 42 (11): 1911–1923. doi:10.1016/j.soilbio.2010.07.021. PMC PMC2976544. PMID 21076656.
- ^ Parachin, Nádia; Gorwa-Grauslund, Marie F (2011). “Isolation of xylose isomerases by sequence- and function-based screening from a soil metagenomic library” (英語). Biotechnology for Biofuels 4 (1): 9. doi:10.1186/1754-6834-4-9. ISSN 1754-6834. PMC 3113934. PMID 21545702.
- ^ “Culture-independent discovery of the malacidins as calcium-dependent antibiotics with activity against multidrug-resistant Gram-positive pathogens”. Nature Microbiology 3 (4): 415–422. (April 2018). doi:10.1038/s41564-018-0110-1. PMC 5874163. PMID 29434326.
- ^ “Toward molecular trait-based ecology through integration of biogeochemical, geographical and metagenomic data”. Molecular Systems Biology 7: 473. (March 2011). doi:10.1038/msb.2011.6. PMC 3094067. PMID 21407210.
- ^ “High nutrient transport and cycling potential revealed in the microbial metagenome of Australian sea lion (Neophoca cinerea) faeces”. PloS One 7 (5): e36478. (2012). Bibcode: 2012PLoSO...736478L. doi:10.1371/journal.pone.0036478. PMC 3350522. PMID 22606263.
- ^ a b Metagenomics : theory, methods, and applications. Marco, Diana.. Wymondham: Caister Academic Press. (2010). ISBN 978-1-904455-54-7. OCLC 351318426
- ^ “A human gut microbial gene catalogue established by metagenomic sequencing”. Nature 464 (7285): 59–65. (March 2010). Bibcode: 2010Natur.464...59.. doi:10.1038/nature08821. PMC 3779803. PMID 20203603.