
データモデル

データモデルは、アプリケーション設計のための計画として使うソフトウェア工学の抽象モデルの1つである。班・要員間の意思疎通のための事業データの文書化、組織化、そして特にデータの格納方法や利用方法のために利用される。
Hoberman(2009)によれば、「データモデルは、組織内での意思疎通を改善し、それによってより柔軟で安定したアプリケーション環境に導く、真の情報の部分集合を正確に説明するシンボルとテキストの集合を使う、事業とIT専門家の両方のための、道筋を見つける道具である。」[2]
データモデルは、データまたは構造化データの構造を明示的に決める。データモデルの代表的な応用は、データベース・モデル、情報システムの設計、およびデータの交換を可能にすることを含む。通常データモデルは、データモデリング言語によって規定する[3]。
コミュニケーションと精度は、データモデルがデータを使い交換する応用へもたらす2つの主要な利益である。データモデルは、異なる背景と異なる経験水準からなる事業要員がお互い意思疎通する媒体である。精度は、データモデルにおける用語と規則をただ1つの方法で解釈することができ、そして曖昧さが無いことを仮定する[2]。
データモデルは、時には、特にプログラミング言語の文脈における、データ構造として参照する。データモデルは、エンタープライズモデルの文脈で、しばしば、機能モデルで補完する。
概要[編集]
大量の構造化されたデータや構造化されないデータを管理することは、情報システムの主要な機能である。データモデルは、リレーショナル・データベースのようなデータ管理システムでの記憶装置のための構造化されたデータを記述する。それらは、典型的に、ワードプロセッサ文書、電子メール、ピクチャ、音声あるいはビデオのような、非構造化データを記述しない。
データモデルの役割[編集]

データモデルの主な目的は、データの定義とフォーマットを提供することによって、情報システムの開発を支援することである。WestとFowler(1999)によれば、「もしこれがシステムを通して一貫して行われたら、そこでデータの互換性が達成されうる。もし同じデータ構造がデータの格納やアクセスに使われるなら、そこで異なるアプリケーションがデータを共有できる。これの結果は上で示される。しかしながら、システムとインタフェースは、しばしば、構築し、運用し、そして維持するため、それらがあるべきより多くのコストを費やす。それらは、事業を支援するよりむしろ制約するかもしれない。1つの大きな原因は、システムとインタフェースに実装されるデータモデルの品質が貧弱だったことである。」[4]
- 「どのように物事が、特定の場所で行われるかを特定する事業ルールはしばしばデータモデルの構造に固定化される。これは、事業を行う方法における小さな変化がコンピュータ・システムおよびインタフェースにおける大きな変更を導き出すことを意味する。」[4]
- 「エンティティ・タイプは、多くの場合識別されないか、あるいは不正確に識別される。これは、データ、データ構造、および機能性の、その開発や保守における重複する付随的コストを伴う、重複を導きうる。」[4]
- 「異なるシステムのためのデータモデルは任意的に異なる。この結果は、複雑なインタフェースが、データを共有するシステム間で要求される。これらのインタフェースは、現状システムのコストの25-70%の間で説明できる。」[4]
- 「データは、データの構造や意味が標準化されていないので、顧客と供給者と電子的に共有することはできない。たとえば、プロセス・プラントのエンジニアリング・データと図面は、未だに時には紙ベースで交換されている。」[4]
これらの問題の理由は、データモデルが事業ニーズと一貫性を保つことの両方に合致することを確かにする標準が不足していることである[4]。
3つの観点[編集]

データモデルインスタンスは、1975年のANSIに沿った3つの種類の1つかもしれない[5]。
- 概念スキーマ:モデルのスコープである、1つのドメインの意味を記述する。たとえば、それは1つの組織あるいは産業の関心領域のモデルかもしれない。これは、そのドメインにおける重要なものの種類を表現するエンティティ・クラスと、一対のエンティティ・クラス間の関連について関連からなる。概念スキーマは、そのモデルを使って表されうる、事実と命題の種類を特定する。そのセンスで、それは、そのモデルのスコープによって限定される1つのスコープの、1つの人工的'言語'で許される表現を定義する。概念スキーマの利用は、事業ユーザーと共に強力なコミュニケーション・ツールとなるよう進化する。しばしば、「主題領域モデル(SAM)」または「ハイレベル・データモデル(HDM)」と呼ばれるこのモデルは、事業ユーザーが全体的アプリケーション開発または事業体イニシアティブの一部として、コア・データ概念、ルール、および定義をコミュニケートするのに使われる。オブジェクトのいくつかは、少なくかつ主要な概念に焦点を当てるべきである。大変大きな組織や複雑なプロジェクトのため、モデルは2ページ以上にまたがるかもしれないが、1ページにこのモデルを限定しようと試みる必要がある[6]。
- 論理スキーマ:特定のデータ操作技術によって表現されるような、意味論を記述する。これは、他のものの間の、テーブルおよびカラム、オブジェクト指向クラス、およびXMLタグの解説からなる。
- 物理スキーマ:データが格納される物理的手段を記述する。これは、パーティション、CPU、表空間、あるいはそのようなことに係わる。
ANSIによれば、このアプローチの重要性は、3つの観点がそれぞれ相対的に独立であることを可能にすることである。格納技術は、論理的あるいは概念モデルのいずれにも影響することなく変更できる。テーブル/カラム構造は、概念モデルに(必要なら)影響することなく変更できる。いずれの場合も、もちろん、その構造は他のモデルとの一貫性を残さなければならない。テーブル/カラム構造は、エンティティ・クラスや属性の直接変換からは異なるかもしれないが、しかし、それは究極的に概念エンティティ・クラス構造の目的の外で扱わなくてはならない。多くのソフトウエア開発プロジェクトの初期段階は、概念データモデルの設計を強調する。このような設計は、論理データモデルで詳細化される。その後段で、このモデルは、物理データモデルに変換されるかもしれない。しかしながら、概念モデルを直接実装することも可能である。
歴史[編集]
情報システムのモデリングにおける最も初期の業績の1つは、「情報を規定する正確で抽象的な方法とデータ処理問題の時間的特徴」を論じた、YoungとKent(1958)によって為された[7][8]。彼らは、「ハードウエアのあらゆる部分を取り巻く問題のための分析者に可能となるべき1つの表記法」を作ることを望んだ。彼らの作業は最初、異なるハードウエア・コンポーネントを使う異なる代替的実装を設計するための、1つの抽象仕様と不変の基盤を作る努力であった。情報システム・モデリングにおける次のステップは、「データ処理のシステム・レベルで、マシン独立の問題定義言語の正しい構造」を開発すると言う、本質的にYoungとKentと同じことを目指した、1959年に編成されたIT業界コンソーシアムである、CODASYLによって行われた。これが1つの特定な情報システムの情報代数学(en:Information_algebra)の開発に導いた[8]。
1960年代にデータモデリングは、経営情報システム概念の導入と共に更にその重要性を増大させた。Leondes(2002)によれば、「必要なとき、情報システムは、管理目的のためデータと情報を提供する。このIntegrated_Data_Store (IDS)と呼ばれる、第一世代データベースシステムが、GEのチャールズ・バックマンによって設計された。2つの有名なデータベース・モデル:ネットワーク型データモデル、および階層型データモデルがこの期間中に提案された。」[9]1960年代の終わりに向けて、エドガー・F・コッドは、彼のデータ編成の理論を練り、一階述語論理に基づいたデータベース管理のためのリレーショナル・モデルを提案した[10]。
1970年代に実体関連モデルが、1976年にピーター・チェンによって初めて提案され、概念データモデルの新しいタイプとして出現した。実体関連モデルは、データベースに格納される情報ニーズや情報のタイプを記述するための、要求分析中の情報システム設計の最初のステージで使われた。この技術は、あらゆる概念体系、すなわち、一定の関心の領域のための、概念の全貌と分類とそれらの関連、を記述できる。
1970年代、G.M. Nijssenは、「自然言語情報分析手法」(NIAM)を開発し、そして1980年代にそれを発展させたオブジェクト役割モデリング(ORM)をTerry Halpinと一緒に開発した。
Jan L. Harrington(2000)によれば、更に1980年代に、「オブジェクト指向パラダイムの開発が、我々がデータとデータに作用する手続きを見る方法に基本的な変化をもたらした。伝統的に、データと手続きは:データベースにデータとそれらの関連、アプリケーション・プログラムに手続きをと、別々に格納されていた。オブジェクト指向では、しかしながら、そのデータと共にエンティティの手続きを組み合わせた。」[11]
データモデルのタイプ[編集]
データベース・モデル[編集]
データベース・モデル (en:database model) は、どのようにデータベースが構造化され、使われるかを記述する理論または仕様である[12]。いくつかのそのようなモデルが提案されてきた。広く知られたモデルは以下を含む:
- これは、厳密にはデータモデルとして認められないかもしれない。フラット(またはテーブル)モデルは、与えられたカラムの全要素が、同じような値であり、そして1つの行の全要素が互いに関連していると想定される、データ要素の単一の2次元配列で構成される。
- 階層型データモデル:このモデルにおけるデータは、それぞれ同じレベルのリストに特定の順序でレコードを保持するネスト化と並べ替えフィールドを記述するそれぞれのレコードへの単純な上昇リンクを暗示する、ツリー構造に組織化される。
- ネットワーク型データモデル:このモデルは、レコードとセットと呼ばれる、2つの基本的概念を使うデータを組織化する。レコードはフィールドを含み、セットはレコード間の、1は所有者、多はメンバーである、1対多の関連を定義する。
- リレーショナル・モデルは、一階述語論理に基づくデータベース・モデルである。その中核アイデアは、とりうる値と値の組み合わせへの制約を記述する、有限個の述語変数を持つ述語の集合としてデータベースを記述することである[12]:468,467。
- スタースキーマは、データ・ウエアハウス・スキーマの最もシンプルなスタイルである。スタースキーマは、いくつかの「事実テーブル」(おそらく1つのみであり、その名前を正当化する)がどんな数の「次元テーブル」を参照する。スタースキーマは、重要な雪形スキーマの特別なケースと考えられる。





データ構造ダイアグラム[編集]

データ構造ダイアグラム(DSD)は、エンティティとそれらの関連、およびそれらを拘束する制約(constraints)を文書化する図式表記法を提供することによって、概念データモデルを記述するため使われる1つのダイアグラムでありデータモデルである。DSDの基本的図形要素は、エンティティを表すボックスと、関連を表す矢である。データ構造ダイアグラムは、複雑なデータ・エンティティを文書化するため最も有用である。
データ構造ダイアグラムは、実体関連モデルの1つの拡張である。DSDで、関連が、エンティティ群を束ねる制約を規定する属性から構成されるボックスとして描かれる一方で、属性は、エンティティの、外側でなく、内側で規定される。実体関連モデルは、堅牢である一方で、関連同士の制約を規定する方法を提供せず、そして、いくつかの属性を持つエンティティを表現するとき視覚的に扱い難くなる。DSDは、DSDが1つのエンティティ内での要素の関連に焦点を当て、そしてユーザーに各エンティティ間のリンクと関連を完全に見せることができるのに対して、実体関連モデルでは異なるエンティティ間の関連に焦点を当てる点で、異なる。
データ構造ダイアグラムを表現するため、多重度(cardinality)を定義する方法に顕著な違いを伴う、いくつかのスタイルがある。選択は、鏃、逆向き鏃(鳥足)、あるいは多重度の数値表現の間に存在する。

実体関連モデル(ERM)[編集]
実体関連モデル(ERモデル)は、構造化されたデータを表現するためソフトウエア工学で使われる、1つの抽象概念スキーマ(または、意味的データモデル(semantic data model))である。実体関連モデルのため使われるいくつもの表記法が存在する。
地理的データモデル[編集]
地理情報システムにおけるデータモデル(data model)は、データとして地理的オブジェクトまたは地表を表現するための数学的概念である。たとえば、以下のような例がある。
- ベクターデータモデルは、点、線、および多角形の集合として地形を表現する
- ラスターデータモデルは、数値を格納するセル・マトリックスとして地形を表現する
- そして不規則三角網(TIN)データモデルは、連続、非重複の三角形のセットとして地形を表現する[14]
![地図作成プロセスに関係するグループ[15]](/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:Groups_relate_to_the_process_of_making_a_map.jpg)
![NGMDB データモデル・アプリケーション[15]](/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:NGMDB_data_model_application.jpg)
![一緒にリンクしたNGMDB データベース[15]](/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:NGMDB_databases_linked_together.jpg)
![3D地図情報の表現[15]](/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:Representing_three-dimensional_map_information.jpg)
汎用データモデル[編集]
汎用データモデル(Generic data model)は、通常のデータモデルの一般化されたものである。それらは、そのような関係タイプによって関連付けられるかもしれないものの種類と一緒に、標準化された一般の関係タイプを定義する。汎用データモデルは、従来のデータモデルの欠点を解決する1つのアプローチとして開発された。例えば、異なるモデラーは一般に、同じドメインの異なる従来のデータモデルを作り出す。これは、異なる人々のモデルを一緒に集めることにおいて困難を導き、そしてデータ交換やデータ統合の障害である。しかしながら、この違いはいつも、モデルにおける抽象レベルの違いと、インスタンス化される事実の種類における違い(モデルの意味的表現能力)に帰因する。モデラーは、違いをより重要でないものにするため、より具体的に提示すべきである一定の要素についてコミュニケートし合意する必要がある。
意味的データモデル(セマンティック・データモデル)[編集]

ソフトウェア工学における意味的データモデル(semantic data model)は、その他のデータとの相互関係性の文脈内でのデータの意味を定義する1つの技法である。意味的データモデルは、どのように格納シンボルがその実世界に関係させるかを定義する1つの抽象である[13]。意味的データモデルは、時には、概念データモデル(conceptual data model)と呼ばれる。
階層型、ネットワーク型データモデル、あるいはリレーショナル であろうと、データベース管理システム(DBMS)の論理的データ構造は、それがスコープとDBMSによって採用される実装戦略への偏った方向における限界があることから、データの概念的定義への要求を完全に満たすことはできない。そこで、概念的ビュー(conceptual view)からデータを定義する必要性が、意味的データモデリング技法の開発に導いた。それは、他のデータとの相互関係性の文脈内でのデータの意味を定義する技法である。図に示されるように。資源、アイデア、イベント、などの条項で、現実世界は、物理的データ・ストア内でシンボル化されて定義される。意味的データモデルは、どのように格納されるシンボルを実世界に関係させるかを定義する1つの抽象である。そこで、そのモデルは実世界の真の表現でなければならない[13]。
データモデルのトピックス[編集]
データアーキテクチャ[編集]
データアーキテクチャは、目標状態の定義に使われるデータの設計であり、かつ目標状態に合致させるため必要とされる次に続く計画である。それは普通、ビジネスアーキテクチャ、またはソリューション仕組(solution architecture)の芯柱を形成するいくつかの仕組ドメイン(architecture domain)の1つである。
データアーキテクチャは、事業あるいはそのアプリケーションによって使われるデータ構造を記述する。データの格納と動きの2つの記述がある。格納におけるデータ記述はデータ・グループとデータ項目を記述し、動きにおけるデータの記述はデータの品質、アプリケーション、場所などへのそれらデータ創作物のマッピングを記述する。
目標状態を実現する上で必須な、データアーキテクチャの記述はどのようにデータが、与えられたシステム内で、処理され、格納され、取扱われるかである。それは、そのシステム内での、データ・フローを設計し、データの流れをコントロールすることも可能にするデータ処理運用のための基準を提供する。
データモデリング[編集]

ソフトウエア工学における データモデリングは、データモデリング技法を使って公式のデータモデル記述を適用することによるデータモデルを作成するプロセスである。データモデリングは、データベースのための事業要求を定義するための1つの技法である。それは時には、1つのデータモデルがやがて1つのデータベースに実装されることから、データベース・モデリングと呼ばれる[16]。
図は、今日のデータモデルが開発され、そして使われる方法を描いている。概念データモデル(conceptual data model)は、開発されているアプリケーションのためのデータ要求に基づき、おそらくアクティビティ・モデルの文脈で開発される。そのデータモデルは通常、エンティティ・タイプ、属性、関連、完全性ルール、およびそれらのオブジェクトの定義から成る。これは、そこでインタフェースまたはデータベース設計のためのスタート・ポイントとして使われる[4]。
データ特性[編集]
要求に合致するに必要なデータのいくつか重要な特性は:
- 定義関連の特性[4]
- 関連性: あなたの事業の文脈でのそのデータの有用性。
- 明快さ: そのデータの明快で共有される定義の利用性。
- 一貫性: 異なる情報源からのデータのタイプの互換性。

- 内容関連の特性
- 適時性: 要求される時のデータの利用可能性と、どのようにデータが更新されるか。
- 正確さ: どのようにそのデータが真実に近づくか。
- 定義と内容の両方に関連する特性
- 完全性: どれだけ要求されるデータが利用可能か。
- アクセス性: どこで、如何に、誰に、データが利用可能であり、可能ではないか(すなわちセキュリティ)。
- コスト: そのデータを取得し、利用可能にするのに許されるコスト。
データ組織化[編集]
データモデルのもう1つの種類は、データベース管理システムまたは他のデータ管理技術を使って、どのようにデータを組織化するかを記述する。それは、例えば、リレーショナル・テーブルとカラムまたはオブジェクト指向クラスと属性を記述する。そのようなデータモデルは、時には、物理データモデル(physical data model)として参照されるが、ANSIのオリジナルの3層スキーマ仕組でそれは「論理的」と呼ばれる。その仕組において、その物理的モデルは、格納媒体(シリンダー、トラック、およびテーブル空間)を記述する。理想的にこのモデルは、上で記述されたより概念的なデータモデルから派生される。それは異なるかもしれないが、しかしながら、処理能力た用途パターンのような制約を記録する。
データ分析がデータモデリングの共通の用語である一方で、実際的な活動は、それが(より一般的な概念から構成要素の概念を識別する)分析を伴って行われるより、(特定のインスタンスから一般の概念を推定する)合成の考えや手法を伴うのがより共通である。{おそらく誰もシステム合成者と呼ばないことから、我々が我々自身をシステムアナリストと呼ぶ。} データモデリングは、不必要なデータの冗長性を排除し、関連でデータ構造を関連付けることで全体を、緊密し、分離不可に、一緒の関心のデータ構造にする努力をする。
1つの異なるアプローチは、データの暗黙的モデルを自律的に作り出す人工ニューラル・ネットワークのような、適合システム(adaptive systems)の利用を通してである。
データ構造[編集]

データ構造は、データを効率的に使えるようコンピュータに格納する1つの方法である。それは、データの数学的かつ論理的な概念の1つの組織化である。しばしば、注意深く選ばれたデータ構造が、最も効率的なアルゴリズムの利用を可能とする。データ構造の選択はしばしば、抽象データ型の選択から始まる。
データ・モデルは、与えられたドメイン内のデータの構造を、そのドメイン自身の基盤をなす構造をほのめかすことによって、記述する。これは、そのドメインに専用の人工言語の専用文法を、実際に規定することを意味する。データモデルは、企業が保持しようと望む情報、その情報の属性、およびそれらのエンティティ間の関連と(時には暗示的に)それらの属性間の関連についての、エンティティのクラス(ものの種類)を表現する。そのモデルは、どのようにデータがコンピュータ・システム内で表現されるかにかかわらず、いくらかの広がりへのデータの組織を記述する。
データモデルによって表現されるエンティティは、触知可能なエンティティであり得るが、そのような具体的エンティティ・クラスを含むモデルは、時間を越えて変化する傾向がある。堅牢なデータモデルは、しばしばそのようなエンティティの抽象概念を認識する。たとえば、1つのデータモデルが、ある組織と関連する全ての人間を表す、「人材」と呼ばれるエンティティ・クラスを含むかもしれない。そのような抽象エンティティクラスは、それらの人材によって演じられる特定の役割を識別する「ベンダー」または「従業員」と呼ばれるより、一般に適切である。
-
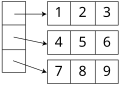 配列
配列 -

-
-




データモデル理論[編集]
用語「データモデル」は、次の2つの意味を持ち得る[17]。
- データモデル理論、すなわち、どのようにデータが構造化されそしてアクセスされるかの形式的な記述。
- データモデルインスタンス、すなわち、ある特定なアプリケーションのための特定なデータモデルインスタンスを生成するためにデータモデル理論を適用すること。
データモデル理論は、次の3つの主要なコンポーネントを持つ[17]。
- 構造部分:データベースによってモデル化されたエンティティまたはオブジェクトを表現するデータベースを生成するため使われるデータ構造の集合。
- 完全性部分:構造的な完全性を確実にするこれらのデータ構造におかれる制約を統治するルールの集合。
- 操作部分:データ構造に適用され、データベースに含まれるデータを更新しクエリする操作の集合。
例えば、関係モデルにおける、構造部分は数学的関係を修正した概念に基づき、完全性部分は一階述語論理で表現され、そして操作部分は 関係代数、タプル関係論理、および ドメイン関係論理を使って表現される。
データモデル・インスタンスは、データモデル理論を適用することで生成される。これは典型的に、ある事業の事業体要求を解決する。事業要求は、通常意味的論理モデル(logical data model)によって獲得される。これは、物理的データベースに生成されることから、物理的データモデル・インスタンスに変換される。例えば、データ・モデラーは、いくつかの事業の事業体の企業データ・リポジトリの実体関連モデルを生成するため、データモデリング・ツールを使う。このモデルは、リレーショナル・データベースを生成するため、リレーショナル・モデルに変換される。
パターン[編集]
パターンは、多くのデータモデルで現れる共通のデータモデリング構造である[18]。
関連モデル[編集]
データ・フロー・ダイアグラム(DFD)[編集]

データ・フロー・ダイアグラムは、プログラムのコントロールの流れを示すフローチャートとは違い、情報システムを通してのデータの「流れ」を示す、図式表現である。データ・フロー・ダイアグラムはまた、データ処理(構造化設計)の可視化(visualization)のため使われうる。データ・フロー・ダイアグラムは、MartinとEstrinの コンピュータの「データ・フロー・グラフ」に基づいた構造化設計のオリジナル開発者である、Larry Constantine(Larry Constantine)によって考案された[20]。
それは、システムと外側のエンティティ間の相互作用を最初に示す、文脈レベル・データ・フロー・ダイアグラム(context-level Data flow diagram)を描く共通の実践である。DFDは、どのようにシステムが、分割された部分間のデータの流れに着目してより小さな部分に分割するかを示すため設計される。この文脈レベル・データ・フロー・ダイアグラムは、そこでモデル化されているシステムをより詳細に示すため「激増」される。
情報モデル[編集]

情報モデルは、データモデルの一つのタイプではないが、一つの代替モデルより多いかまたは少ない。ソフトウエア工学の分野でのデータモデルと情報モデルの両方は、特性、関連、およびそれらで実行され得る操作を含め、エンティティ・タイプの抽象であり、公式表現である。モデル内のエンティティ・タイプは、ネットワーク内の機器のような、実世界のオブジェクトの種類かもしれないし、またそれらは、勘定システム内で使われるエンティティのような、抽象化されたそれら自身かもしれない。典型的に、それらは、エンティティ・タイプ、特性、関連、および操作の閉じたセットによって記述される、制約されたドメインをモデル化するのに使われる。
Lee(1999)によれば[21] 、情報モデルは、選ばれた概説のドメインのデータ意味論(data semantics)を規定する、概念、関連、制約、ルール、あるいは演算子の表現である。 それは、そのドメインの文脈のための共有性、安定性、および情報要求の組織化された構造を提供する[21]。一般的用語情報モデルはさらに、施設、ビルディング、プロセス・プラントなどのような、個々のもののモデルのため使われる。このような場合、概念は、ファシリティ情報モデル(Facility Information Model)、ビルディング情報モデル(Building Information Model)、プラント情報モデルなどと特定される。そのような情報モデルは、施設についてのデータと文書を伴う施設のモデルの統合である。
情報モデルは、どのようにその記述がソフトウエアにおいて実際の実装にマップされたかの記述を制約することなく、問題ドメイン記述の形式主義を提供する。情報モデリングのマッピングには多くもものが存在する。そのようなマッピングは、それらが(UMLを使った)オブジェクトモデル(object model)、実体関連モデル、または XMLのスキーマ(XML schema)であるかどうかにかかわらず、データモデルと呼ばれる。

オブジェクト・モデル[編集]
コンピュータ科学におけるオブジェクト・モデル(object model)は、プログラムがその世界のある特定な部分を試しそして操作できるオブジェクトあるいはクラスの集合である。言い換えるなら、ある種のサービスまたはシステムへのオブジェクト指向インタフェースである。そのようなインタフェースは、表現されたサービスまたはシステムのオブジェクト・モデルであると言える。たとえば、Document Object Model[2]は、ページを調べて動的変化をプログラムするスクリプトを使う、ウェブブラウザにおけるページ表現の集合である。Microsoft Excelを他のプログラムからコントロールするための、Microsoft Excelオブジェクト・モデルが存在するし、また、ASCOM(AStronomy Common Object Model)Telescope Driver[22] は、天体望遠鏡をコントロールするための1つのオブジェクト・モデルである。
コンピューティングにおける用語オブジェクト・モデルは、プログラミング言語技術、表記法、または 方法論を使うある特定なコンピュータにおけるオブジェクトの一般的特性とは別の2番目の意味をもつ。例は: Javaオブジェクト・モデル、 Component Object Model、あるいは、 オブジェクトモデル化技法(OMT)。このようなオブジェクト・モデルは通常、 クラス、メッセージ、継承、多態性、 情報隠蔽のような概念を使って定義される。プログラミング言語の形式意味論 のサブセットとして形式化されたオブジェクト・モデルに関する膨大な文献が存在する。
オブジェクト役割モデル[編集]

オブジェクト役割モデリング(ORM)は、概念的モデリング(conceptual modeling)のための1つの手法であり、情報やルールの分析のための1つのツールとして利用できる[24]。
オブジェクト役割モデリングは、概念レベルでのシステム分析のための1つの事実指向の手法である。データベース・アプリケーションの品質は、その設計に重大に依存する。正しさ、明確さ、適合性、および生産性を確かにするのを助けるため、情報システムは、人々が容易に理解できる概念と言語を使って概念レベルで最初に規定されることがベストである。
概念的設計は、データ、プロセス、および振る舞い的観点を含むかもしれないし、その設計を実装のため使われた実際のDBMSは、(リレーショナル、階層型、ネットワーク型、オブジェクト指向等の)多くの論理的データモデルの1つに基づいたかもしれない[25]。
統一モデリング言語モデル[編集]
統一モデリング言語(UML)は、ソフトウエア工学分野での、1つの標準汎用モデリング言語である。それは、ソフトウエア集約システムの成果物(ソフトウエア開発)(artifacts)を、可視化し、規定し、構築し、そして文書化するための1つの図式言語(graphical language)である。統一モデリング言語は、以下を含む、システムの青写真を描く標準方法を提供する[26]。
- 事業プロセスやシステム機能のような概念的なもの
- プログラミング言語のステートメント、データベース・スキーマのような具体的なもの
- 再利用可能なソフトウェアコンポーネント。
UML は、機能モデル、データモデル、およびデータベースモデル(database model)の1つのミックスを提供する。
関連項目[編集]
- データベース設計
- ビジネスプロセスモデリング
- Core Architecture Data Model (コア仕組データモデル)
- データベース・システム(Database system)
- データ辞書
- ダイアグラム
- エンタープライズモデリング
- 実体関連モデル
- 機能モデル
- IDEF1X
- 情報モデル
- 情報システム
- JC3IEDM(JC3IEDM)
- オントロジー(情報科学)
- プロセス・モデリング
- XMLのスキーマ(XML schema)
- データ・フォーマット記述言語(DFDL)
脚注[編集]
- ^ Paul R. Smith & Richard Sarfaty (1993). Creating a strategic plan for configuration management using Computer Aided Software Engineering (CASE) tools. Paper For 1993 National DOE/Contractors and Facilities CAD/CAE User's Group.
- ^ a b "Data Modeling Made Simple 2nd Edition", Steve Hoberman, Technics Publications, LLC 2009
- ^ Michael R. McCaleb (1999). "A Conceptual Data Model of Datum Systems". National Institute of Standards and Technology. August 1999.
- ^ a b c d e f g h i j k Matthew West and Julian Fowler (1999). Developing High Quality Data Models Archived 2008年12月21日, at the Wayback Machine.. The European Process Industries STEP Technical Liaison Executive (EPISTLE).
- ^ American National Standards Institute. 1975. ANSI/X3/SPARC Study Group on Data Base Management Systems; Interim Report. FDT (Bulletin of ACM SIGMOD) 7:2.
- ^ "Data Modeling for the Business", Steve Hoberman, Donna Burbank, Chris Bradley, Technics Publications, LLC 2009
- ^ Young, J. W., and Kent, H. K. (1958). "Abstract Formulation of Data Processing Problems". In: Journal of Industrial Engineering. Nov-Dec 1958. 9(6), pp. 471-479
- ^ a b Janis A. Bubenko jr (2007) "From Information Algebra to Enterprise Modelling and Ontologies - a Historical Perspective on Modelling for Information Systems". In: Conceptual Modelling in Information Systems Engineering. John Krogstie et al. eds. pp 1-18
- ^ Cornelius T. Leondes (2002). Database and Data Communication Network Systems: Techniques and Applications. Page 7
- ^ "Derivability, Redundancy, and Consistency of Relations Stored in Large Data Banks", E.F. Codd, IBM Research Report, 1969
- ^ Jan L. Harrington (2000). Object-oriented Database Design Clearly Explained. p.4
- ^ a b 高浜, 忠彦「情報処理技術と数学〔第6回〕 データベースの数学モデル」『情報管理』第21巻第6号、1978年、462頁、doi:10.1241/johokanri.21.462、ISSN 1347-1597。
- ^ a b c d FIPS Publication 184 released of IDEF1X by the Computer Systems Laboratory of the National Institute of Standards and Technology (NIST). 21 December 1993.
- ^ Wade, T. and Sommer, S. eds. A to Z GIS
- ^ a b c d David R. Soller1 and Thomas M. Berg (2003). The National Geologic Map Database Project: Overview and Progress U.S. Geological Survey Open-File Report 03–471.
- ^ Whitten, Jeffrey L.; Lonnie D. Bentley, Kevin C. Dittman. (2004). Systems Analysis and Design Methods. 6th edition. ISBN 025619906X.
- ^ a b Beynon-Davies P. (2004). Database Systems 3rd Edition. Palgrave, Basingstoke, UK. ISBN 1-4039-1601-2
- ^ "The Data Model Resource Book: Universal Patterns for Data Modeling" Len Silverstone & Paul Agnew (2008).
- ^ John Azzolini (2000). Introduction to Systems Engineering Practices. July 2000.
- ^ W. Stevens, G. Myers, L. Constantine, "Structured Design", IBM Systems Journal, 13 (2), 115-139, 1974.
- ^ a b Y. Tina Lee (1999). "Information modeling from design to implementation" National Institute of Standards and Technology.
- ^ [1]
- ^ Stephen M. Richard (1999). Geologic Concept Modeling. U.S. Geological Survey Open-File Report 99-386.
- ^ Joachim Rossberg and Rickard Redler (2005). Pro Scalable .NET 2.0 Application Designs.. Page 27
- ^ Object Role Modeling: An Overview (msdn.microsoft.com). Retrieved 19 September 2008.
- ^ Grady Booch, Ivar Jacobson & Jim Rumbaugh (2000) OMG Unified Modeling Language Specification, Version 1.3 First Edition: March 2000. Retrieved 12 August 2008.
文献案内[編集]
- David C. Hay(1996). Data Model Patterns: Conventions of Thought. New York:Dorset House Publishers, Inc.
- Matthew West and Julian Fowler(1999). Developing High Quality Data Models. The European Process Industries STEP Technical Liaison Executive(EPISTLE).
- Len Silverston(2001). The Data Model Resource Book Volume 1/2. John Wiley & Sons.
- RFC 3444 - On the Difference between Information Models and Data Models
- Len Silverston & Paul Agnew(2008). The Data Model Resource Book: Universal Patterns for data Modeling Volume 3. John Wiley & Sons.
- Steve Hoberman, Donna Burbank, & Chris Bradley(2009). Data Modeling for the Business. Technics Publications, LLC
- Andy Graham(2010), The Enterprise Data Model: a framework for enterprise data architecture
| メイン | |
|---|---|
| スキーマ | |
| タイプ | |
| 関連モデル | |
| 関連項目 | |
| 分野 | |||||||
|---|---|---|---|---|---|---|---|
| コンセプト | |||||||
| 指向 | |||||||
| モデル |
| ||||||
| 主な人物 | |||||||
| 関連項目 | |||||||