グローバーのアルゴリズムとは、N個の要素をもつ未整序データベースの中から指定された値を検索する探索問題を解くための量子コンピュータのアルゴリズムであり、O(N1/2)のオーダーの計算量と、O(logN)のオーダー(ランダウの記号も参照)の記憶領域を消費する。1996年にロブ・グローバー(英語版)によって開発された。
典型的には、未整序データベースからの探索は、O(N)の計算時間を要する線型探索を用いなければならない。グローバーのアルゴリズムは、O(N1/2)の計算時間しか消費せず、未整序データベース探索を行う量子アルゴリズムの中で最も速い[1]。
このアルゴリズムは他の量子アルゴリズムがしばしば、古典アルゴリズムと比較して指数的な速度向上をもたらすのとは異なり、二次の速度向上しかもたらさない。しかし、Nが大きければ、二次の向上でもかなりの向上となる。たとえば、グローバーのアルゴリズムを共通鍵暗号の総当り攻撃に利用すると、128ビット鍵であれば264の繰り返しで、256ビット鍵であれば2128の繰り返しで求めることができる。このため、将来の量子総当り攻撃に対して安全性を持たせるために、鍵長を2倍にすることが提案されている[2]。
他の量子アルゴリズムと同じように、グローバーのアルゴリズムは正しい解を高い確率で与える確率的アルゴリズムである。この解が正しくない確率は、このアルゴリズムを繰り返すことによって減少させることができる(確率的アルゴリズムでない、正しい確率が1の解を与える、決定的アルゴリズムについてはドイッチュ・ジョサのアルゴリズムを参照)。
グローバーのアルゴリズムの目的は普通「データベース探索」とされるが、「逆関数の導出」と言うとより正確かもしれない。おおざっぱにいうと、y=f(x)という量子コンピュータで処理できる関数があったとして、このアルゴリズムを使うとあるyを与えるxの値を計算することができる。データベース探索は、データベースをインデックスxに対してデータyを与える関数と考えれば、逆関数を求めることと同値である。
グローバーのアルゴリズムは、平均と中央値を推定すること、また衝突問題(w:Collision problem)を解くのにも使える。また、可能性のある解を総当たりで探すことによってNP完全問題を解くことにも使える。これは、膨大な可能性を試すのに、重ね合わせを用いることで限られた計算量しか消費しないので、古典アルゴリズムに比べてかなりのスピードアップを見込めるが、指数時間かかってしまうことは変らない。あらかじめ解が複数あることとその個数がわかっている場合、このアルゴリズムはさらに高速化することができる。
N個のデータを持つデータベースを考える。データベースの中から、何らかの検索条件を満たすデータを探し出す問題を考えよう。
グローバーのアルゴリズムは、 次元の状態空間
次元の状態空間  を必要とする。これは
を必要とする。これは 量子ビットあれば満され、基底状態は
量子ビットあれば満され、基底状態は

と書ける。これらの固有値  は全て異なるとする。
は全て異なるとする。
 を、データベースのインデクス
を、データベースのインデクス  を入力すると、検索条件を満たしているか否かを判定する関数とする。例えば、値
を入力すると、検索条件を満たしているか否かを判定する関数とする。例えば、値  に対して
に対して![{\displaystyle D[x]=v}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f6b122869017b257f0dc293aef98465053d5edaa) となる
となる  を探したい場合には、
を探したい場合には、
![{\displaystyle {\begin{cases}f(x)=1&{\text{ if }}D[x]=v,\\f(x)=0&{\text{ if }}D[x]\neq v\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fc26276e8c6b49894500fc6f3a8234d04e66970b)
である。以下では  を、
を、 を満たす値とし、次のようにふるまうユニタリ演算子
を満たす値とし、次のようにふるまうユニタリ演算子  を自由にサブルーチンとして使えるとする。(このサブルーチンは、オラクルとも呼ばれる。)
を自由にサブルーチンとして使えるとする。(このサブルーチンは、オラクルとも呼ばれる。)

アルゴリズムの目的は、インデクス  を特定することである。
を特定することである。
なお、(下に示す量子回路のように)補助量子ビットシステムを使う場合には、演算子 の定義は異なるものになる。この場合の演算子は、メインシステムの  の値(0か1)に応じて反転させる制御NOTによって
の値(0か1)に応じて反転させる制御NOTによって

あるいは、

で表現される。
アルゴリズムの流れ[編集]
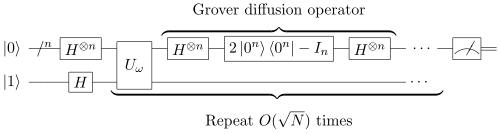 グローバーのアルゴリズムを表す量子回路
グローバーのアルゴリズムを表す量子回路
 を、全ての状態の一様な重ね合わせ
を、全ての状態の一様な重ね合わせ

とし、演算子  を
を

とする。この演算子は、グローバーの拡散演算子と呼ばれている。
グローバーのアルゴリズムの流れは以下の通りである。
- 初期状態を以下の様に用意する:

- 次にしめす"Grover iteration"を
 回繰返す。関数 は漸近的に
回繰返す。関数 は漸近的に  である関数であり、詳細は後述する。
である関数であり、詳細は後述する。
- 演算子 を適用する。
- 演算子 を適用する。
- 状態Ωを観測する。観測の結果は、Nが十分に大きければ、1に近い確率でλωとなり、を得ることができる。
1回目の繰り返し[編集]
演算子 は

で定義されており、さらに、演算子 は次のように書くことができることに注意する。

これを確認するには、 が基底状態に対してどのように作用するかをチェックしてみればよい。
が基底状態に対してどのように作用するかをチェックしてみればよい。

さらに、 は基底状態で、 は全ての状態の一様な重ね合わせであるから、

が成り立つ。したがって、1回目の繰り返しでは次にように計算される。

分かりやすい例として、 が4で、条件を満たす(つまり を満たす) が一つしかない場合を考えてみると、 となり、Grover iterator を一回作用させただけで目的の状態を得ることができることが分かる。
となり、Grover iterator を一回作用させただけで目的の状態を得ることができることが分かる。
一般の場合では、 と を作用させることで、目的の状態の二乗振幅は  から
から  に増加する。
に増加する。
妥当性の幾何学的な証明[編集]
 グローバーのアルゴリズムの最初の繰り返しの幾何学的な解釈。状態ベクトル は、この図のように目的のベクトル に近づく。
グローバーのアルゴリズムの最初の繰り返しの幾何学的な解釈。状態ベクトル は、この図のように目的のベクトル に近づく。
|s>と|ω>で張られる空間を考える。この平面は、 と,それと直交する  で張られる空間と等しい。
初期状態 に作用する最初の繰り返しを考えよう。 は基底ベクトルであるから、 と
で張られる空間と等しい。
初期状態 に作用する最初の繰り返しを考えよう。 は基底ベクトルであるから、 と  の重なりは次のようになる。
の重なりは次のようになる。

幾何学的に言えば、 と のなす角度  は次の関係を満す。
は次の関係を満す。

演算子Uωは、|s>と|ω>で張られる空間を、|ω>と垂直な超平面を対称面として反転させる。つまり、空間上のベクトルを、 に対して対称なベクトルへ移す。演算子Usは、|s>を対称面とする反転である。よって、|s>と|ω>によって張られる平面上にあるベクトルは、UsとUω で演算されても、その平面上に留まる。また、Grover iterationUsUωの各繰り返しで、状態ベクトルは |ω> に向かって角度  の回転をすることが容易に分かる。
の回転をすることが容易に分かる。
状態ベクトルが|ω>に近付いたなら、繰返しを止めなければならない。繰返しを重ねすぎると、状態ベクトルは|ω>から離れていってしまい、正しい解を与える確率を下げてしまう。 回繰り返した場合に正しい答えが観測される確率は、
回繰り返した場合に正しい答えが観測される確率は、

である。したがって、ほぼ最適な測定が得られる繰り返し回数は  である。
である。
妥当性の代数的な証明[編集]
代数的な解析をするには、 を繰り返し適用したときに何が起こるかを見る必要がある。これは、行列の固有値解析によって見ることができる。アルゴリズムの計算の間、状態は常に
を繰り返し適用したときに何が起こるかを見る必要がある。これは、行列の固有値解析によって見ることができる。アルゴリズムの計算の間、状態は常に  と の線形結合で表されるいることに注意する。そこで、
と の線形結合で表されるいることに注意する。そこで、 によって張られる空間において、 と の動作は次のように表すことができる。
によって張られる空間において、 と の動作は次のように表すことができる。
![{\displaystyle U_{s}:a|\omega \rangle +b|s\rangle \mapsto [|\omega \rangle \,|s\rangle ]{\begin{bmatrix}-1&0\\2/{\sqrt {N}}&1\end{bmatrix}}{\begin{bmatrix}a\\b\end{bmatrix}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8a0b3150cc02d7e7f3205c63c743d543264c6a7b)
![{\displaystyle U_{\omega }:a|\omega \rangle +b|s\rangle \mapsto [|\omega \rangle \,|s\rangle ]{\begin{bmatrix}-1&-2/{\sqrt {N}}\\0&1\end{bmatrix}}{\begin{bmatrix}a\\b\end{bmatrix}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/db5c0718db3b1705bdbd00dc494c2db2c25ebf45)
よって、 を基底とすると(ただし,これらは直交していないし、全体の空間の基底にはなっていない)、 を作用させてから を作用させるという動作 は、次の行列で表せる。
を基底とすると(ただし,これらは直交していないし、全体の空間の基底にはなっていない)、 を作用させてから を作用させるという動作 は、次の行列で表せる。

この行列は、非常に便利なジョルダン標準形をしている。 と定義すれば、
と定義すれば、
 where
where 
と書ける。
これにより、この行列の r 乗(r 回の繰り返しに対応する)は、

となる。この形式を使えば、三角関数の公式を使って、r 回の繰り返しの後に目的の が観測される確率を

と計算することができる。(幾何学的な解析で得た確率と同じ。)
あるいは、最適な繰り返し回数は、角度  と
と  が最も離れているときであり、これは
が最も離れているときであり、これは  に対応する、と考えてもよい。つまり、
に対応する、と考えてもよい。つまり、 が得られる。このとき、システムは
が得られる。このとき、システムは
^{r}{\begin{bmatrix}0\\1\end{bmatrix}}\approx [|\omega \rangle \,|s\rangle ]M{\begin{bmatrix}i&0\\0&-i\end{bmatrix}}M^{-1}{\begin{bmatrix}0\\1\end{bmatrix}}=|\omega \rangle {\frac {1}{\cos(t)}}-|s\rangle {\frac {\sin(t)}{\cos(t)}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/20f60193e79e9db675395c133e7cd361fc31352b)
の状態で終了する。
少し計算すれば、観測によって(エラー確率 O(1/N) を除き)正しい答え が得られることがわかる。
発展形[編集]
もし、探索条件にあうデータが1個だけでなく、k個存在するならば、同じアルゴリズムを適用できるが、繰返し回数はπN1/2/4の代わりにπ(N/k)1/2/4としなければならない。
kが未知の場合を取り扱う方法は幾つかある。例として、繰返し回数を以下のようにしてグローバーのアルゴリズムを何回か走らせる方法がある。

kがどのような値でも、上のような繰返し回数で行えば正しい解を高い確率で得られる。繰返しの総回数は多くとも次のようであり、O(N1/2)のオーダーにとどまる。

このアルゴリズムは改良の余地がある。kが未知であるとして、 のオーダーで解を見付けることができる。このことから、このアルゴリズムは衝突問題を解く目的で使用できる。
のオーダーで解を見付けることができる。このことから、このアルゴリズムは衝突問題を解く目的で使用できる。
最適性[編集]
グローバーのアルゴリズムは最適であることが知られている。つまり、データベースにUωのみを用いてアクセスするようなどんなアルゴリズムも、グローバーのアルゴリズムと同じかそれ以上の回数だけUωを作用させなければならない[1]。この結果は量子計算の限界を理解する上で重要である。
もし、グローバーの探索問題がlogcN回Uω適用することで解くことができるとすれば、NP問題をグローバーの探索問題に帰着させることで、NPがBQPに含まれることが示される。グローバーのアルゴリズムが最適であることは、NPはBQPに含まれないことを示唆している(ただし証明しているわけではない)。
k個の条件に該当するデータがある場合、π(N/k)1/2/4も最適である。
適用可能性と制約[編集]
このアルゴリズムにおいては、データベースは明示的に表されておらず、代わりに、インデクスによってデータで評価するためにオラクルを呼び出す。データベース全体をデータごとに読み込み、それをインデクスを使って評価できる形式に変換することは、グローバーの検索よりもはるかに時間がかかる場合がある。これを考えると、グローバーのアルゴリズムは、方程式や制約充足問題を解くための方法であると見ることができる。このようなアプリケーションでは、オラクルは制約を満たすかどうかをチェックする方法であり、検索アルゴリズムとは無関係に動作する。一方、従来の検索アルゴリズムでは、検索アルゴリズムを制約のチェック方法と合わせて考慮することで総当たりを回避して最適化を行うことが良くある。グローバーのアルゴリズムではこれらが分離しているため、アルゴリズムの最適化が妨げられる。グローバーのアルゴリズムの使用に関するこれらおよびその他の考慮事項は、Viamontes、Markov、およびHayesによる論文で説明されている。[3]
関連項目[編集]
参考文献[編集]
- ^ a b Bennett C.H., Bernstein E., Brassard G., Vazirani U., The strengths and weaknesses of quantum computation. w:SIAM Journal on Computing 26(5): 1510-1523 (1997). Shows the optimality of Grover's algorithm.
- ^ Daniel J. Bernstein (2010-03-03). Grover vs. McEliece. http://cr.yp.to/codes/grovercode-20100303.pdf.
- ^ Viamontes G.F.; Markov I.L.; Hayes J.P. (2005), “Is Quantum Search Practical?”, Computing in Science and Engineering 7 (3): 62–70, arXiv:quant-ph/0405001, Bibcode: 2005CSE.....7c..62V, doi:10.1109/mcse.2005.53, https://web.eecs.umich.edu/~imarkov/pubs/jour/cise05-grov.pdf
|
|---|
| 全般 | |
|---|
| ハードウェア | |
|---|
アルゴリズム•
プログラミング言語 | |
|---|
| 項目 | |
|---|
| 関連分野 | |
|---|
| メーカー | |
|---|
| 実機 | |
|---|
| 人物 | |
|---|
 カテゴリ カテゴリ |


