| この記事は検証可能な参考文献や出典が全く示されていないか、不十分です。出典を追加して記事の信頼性向上にご協力ください。(このテンプレートの使い方)
出典検索?: "非決定性有限オートマトン" – ニュース · 書籍 · スカラー · CiNii · J-STAGE · NDL · dlib.jp · ジャパンサーチ · TWL(2023年9月) |
非決定性有限オートマトン(ひけっていせいゆうげんオートマトン、英: nondeterministic finite automaton、NFA)または非決定性有限状態機械(ひけっていせいゆうげんじょうたいきかい、英: nondeterministic finite state machine)は、有限オートマトンの一種であり、ある状態と入力があったとき、次の遷移先が一意に決定しないことがあるものである。
直感的説明[編集]
NFA は入力文字列を受け付ける。各入力文字を受け付ける度に新たな状態に遷移する。これが全ての文字の入力が終わるまで続く。

非決定性と呼ばれるのは、ある状態からの遷移先が入力文字だけでは一意に定まらない場合があることと、入力文字を受け取らなくても状態遷移する場合があることからである。例えば、状態 S1 にあって文字 a が入力された場合、この文字を受け取らずに状態 S2 に遷移してから a を受け取って状態 S3 に遷移することが可能である。

入力文字を受け取らずに遷移することを「イプシロン遷移」と呼ぶ。一般にギリシャ文字を使って「ε-遷移」と記述する。状態遷移図では、入力文字の代わりに ε を付記する。
最後の入力文字を受け取ったとき、NFA がある特定の状態(受容状態)になった場合のみ、その入力文字列をNFAが受容したと判断される。一方、受容状態以外で終了した場合、その入力文字列は拒否されたと判断される。
形式的定義[編集]
非決定性有限オートマトン (NFA) は、 の5つの要素から構成され、各要素は以下のような性質を持つ。
の5つの要素から構成され、各要素は以下のような性質を持つ。
- 状態の有限集合(
 )
)
- 入力文字の有限集合(
 )
)
- 遷移関数(
 )
)
- 状態
 を特に「初期(または開始)状態」として区別する(
を特に「初期(または開始)状態」として区別する( )
)
- 状態の集合
 を特に「受容(または終了)状態」として区別する(
を特に「受容(または終了)状態」として区別する( )
)
ここで  は の冪集合であり、
は の冪集合であり、 は空の文字列であり、 は入力文字群である。
は空の文字列であり、 は入力文字群である。
 が
が  で構成される NFA で、
で構成される NFA で、 が に含まれる文字で構成された文字列とする。 が文字列 を受容するのは、以下の条件が成立した場合である。まず、 を
が に含まれる文字で構成された文字列とする。 が文字列 を受容するのは、以下の条件が成立した場合である。まず、 を  と表したときに、これを入力された がとる状態遷移が
と表したときに、これを入力された がとる状態遷移が  のようになるとき、以下の条件が成り立つ。
のようになるとき、以下の条件が成り立つ。



マシンは初期状態 から開始され、入力文字列を読み込む。オートマトンは遷移関数  に現在状態と入力文字(あるいは空の文字)を与えて次に遷移すべき状態を得る。しかし、NFA の次の状態は現在の入力イベントのみで決定されるのではなく、その後の任意個数の入力イベント(文字列)にも影響され、NFAが影響される入力イベントが続く限り、次の遷移先を決定することはできない[1]。オートマトンが読み込みを終了したときに受容状態にあれば、NFA はその入力文字列を受容したと言える。さもなくば、その入力文字列は拒否されたと見なされる。
に現在状態と入力文字(あるいは空の文字)を与えて次に遷移すべき状態を得る。しかし、NFA の次の状態は現在の入力イベントのみで決定されるのではなく、その後の任意個数の入力イベント(文字列)にも影響され、NFAが影響される入力イベントが続く限り、次の遷移先を決定することはできない[1]。オートマトンが読み込みを終了したときに受容状態にあれば、NFA はその入力文字列を受容したと言える。さもなくば、その入力文字列は拒否されたと見なされる。
ある NFA が受容する文字列全体の集合が NFA の受容する言語である。この言語は正規言語の範囲に一致する。
NFAとDFAの関係[編集]
任意の NFA には、それと同じ言語を受容する決定性有限オートマトン(DFA)が存在する。実用的なオートマトンを得るために、しばしば NFA は DFA に変換される。
NFA を DFA に変換するには、NFA における上述した の各要素を、DFA における 1状態とすればよい。この変換は部分集合構成法[2]という。しかし最悪の場合、この変換により必要な状態数が指数関数的に増大する。
NFA を実装する方法はいくつか存在する。
- 決定性有限オートマトンに変換する。全ての NFA は DFA に変換可能である。
- 複数の状態への遷移について、配列のようなデータ構造を使って、遷移可能な状態に印を付ける(状態番号をインデックスとする配列)。印が付いている複数の状態が取りうる状態と見なされ、入力にしたがって取りうる全ての状態について遷移先を判断する(ある状態は入力文字を受け付けない場合もあり、その場合その状態は捨てられる)。このようにして最終的に受容状態に印がついていたら、その入力文字列が受容されたと判断できる。
- オブジェクト指向的な実装方法として、NFA をオブジェクトとして、遷移先が複数存在する場合に遷移先の個数ぶんのオブジェクトのコピーを作成してそれぞれに同じ入力文字列(の未入力分)を与えるという方法がある。最終的に受容状態となった NFA オブジェクトが存在したら、その文字列が受容されたと判断できる。現在状態と未入力の入力文字列を引数とした再帰関数の形でも同じことが可能である。
以下では、1 および 0 を入力文字とする NFA を例として示す。 は入力文字列に偶数個の 0 がある場合(最終状態 )と、偶数個の 1 がある場合(最終状態
)と、偶数個の 1 がある場合(最終状態 )を受容する。
)を受容する。
において、

遷移関数 T は以下の状態遷移表で定義される。
|
|

|

|
|

|

|
|

|
|
|

|

|
|

|
|
|
|
|
|

|

|
|

|
|
|
|
M の状態遷移図は以下のようになる。
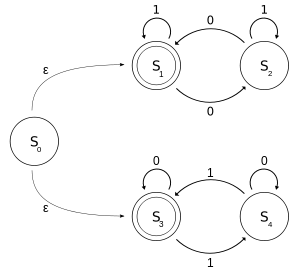
M はふたつのDFAの和集合のようになっている。ひとつのDFAは状態 {S2, S1} を持ち、もうひとつは状態 {S3, S4} を持つ。
- 最終状態 S1 にあるとき、それまでの入力文字列に偶数個の 0 が含まれていたことを意味し、状態 S2 にあるときは奇数個であることを意味する。1 が入力されたとき、上のオートマトンの状態は変化しない。Mが受理されたとき、入力文字列に偶数個の 0 が含まれていた事がわかる。
- 最終状態 S3 にあるとき、それまでの入力文字列に偶数個の 1 が含まれていたことを意味し、状態 S4 にあるときは奇数個であることを意味する。0 が入力されたとき、下のオートマトンの状態は変化しない。Mが受理されたとき、入力文字列に偶数個の 1 が含まれていた事がわかる。
Mの言語は以下の正規表現で記述される正規言語である。

拡張NFA(GNFA)[編集]
拡張非決定性有限オートマトン(GNFA[3])または拡張非決定性有限状態機械[4]とは、各状態遷移が任意の正規表現に対応する NFA である。GNFA は入力からまとめて複数の文字を読み込むが、その文字列は遷移(エッジ)に付記された正規表現に対応するものである。
形式的定義[編集]
GNFA は、 の5要素から構成され、各要素は以下の性質を持つ。
の5要素から構成され、各要素は以下の性質を持つ。
- 状態の有限集合()
- 入力文字の有限集合(Σ)
- 遷移関数(
 )
)
- 開始状態(
 )
)
- 受容状態(
 )
)
ここで  は文字集合 から構成される全ての正規表現の集合である。
は文字集合 から構成される全ての正規表現の集合である。
DFA や NFAは簡単に GNFA に変換でき、GNFA は正規表現に簡単に変換できる。その変換は、中間的な遷移を正規表現に変換していき、最終的に  というひとつの遷移(エッジ)になるようにするものである。同様に GNFA の各遷移(エッジ)に付記された正規表現を一文字ずつに分解するまで中間状態を追加していけば NFA に変換できる。さらに NFA は前述したように DFA に変換可能である。したがって GNFA は DFA および NFA と等価な形式言語を理解する。
というひとつの遷移(エッジ)になるようにするものである。同様に GNFA の各遷移(エッジ)に付記された正規表現を一文字ずつに分解するまで中間状態を追加していけば NFA に変換できる。さらに NFA は前述したように DFA に変換可能である。したがって GNFA は DFA および NFA と等価な形式言語を理解する。
- ^ “Finite State Machine”. FOLDOC. NFA ==> Finite State Machine. 2010年6月16日06:52:21時点のオリジナルよりアーカイブ。2005年11月20日 06:00閲覧。
- ^ A. V. エイホ・R. セシィ、J. D. ウルマン 著、原田 賢一 訳『コンパイラI: 原理・技法・ツール』 1巻、サイエンス社、2000年、139頁。ISBN 4-7819-0585-4。
- ^ 英: generalized non-deterministic finite automaton
- ^ 英: generalized non-deterministic finite state machine

